Rx to Coroutines Concepts, Part 2: Structured Concurrency
Part 1, Async vs. Reactive, Part 2.1, Exceptions, Part 3, Deferred & Channels, Part 4, Cold Flows, Part 5, Shared Flows
Note: This post has been revised since its original publication. The section entitled “Never Inject CoroutineScope” has been renamed “Don’t Inject CoroutineScope (as a property)”, and the text has been revised a bit to reflect this loosening of recommendations.
In the world of RxJava, how to write operator Rx-ese is a frequent topic of discussion. Less often discussed (because it’s not quite so complicated) is how managing concurrent processes works in RxJava.
Concurrent Process Management in RxJava
Let’s give ourselves an example to think with. In Cash App, we write business logic in presenters. Our presenters take in events and emit view models (our view models are Kotlin data classes — just state, that’s it). Doing events right in coroutinesland requires Flow, but that’s a topic for a later post. Let’s do without it for now, and build a presenter for a simple view that only displays things: a view of a single stock.
Our view of a stock displays three things: the ticker, the current price, and a list of articles about the stock.
data class StockViewModel(
val ticker: String,
val stockPrice: String?,
val articles: List<String>,
)
Since it’s Rx, we’ll model the endpoint methods on stockService as Singles:
interface StockService {
fun getQuoteCents(ticker: String): Single<Int>
fun getArticles(ticker: String): Single<List<String>>
}
To start, we’ll create a presenter that shows the ticker, and queries the endpoint that gets the stock price.
class StockPresenter(
val ticker: String,
val stockService: StockService
) {
fun apply(): Observable<StockViewModel> {
return stockService.getQuoteCents(ticker)
.toObservable()
.map { quoteCents ->
val stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
StockViewModel(ticker, stockPrice, emptyList())
}
.startWith(StockViewModel(ticker=ticker, stockPrice=null, articles=emptyList()))
.observeOn(uiThread)
}
}
Now let’s consider this from a standpoint of managing running concurrent work.
First, note that calling apply doesn’t actually do anything. It creates an Observable, which describes the work to be done. By applying operators, our description can assemble workstreams together in a dizzying number of ways.
That’s how other work running in parallel is managed and coordinated. If we want to fetch a list of articles as well, for example, we would do it by combining that work with the existing work with an operator like combineLatest:
fun apply(): Observable<StockViewModel> {
return Observable.combineLatest(
stockService.getQuoteCents(ticker)
.map { it.toOptional() }
.toObservable()
.startWith(None),
stockService.getArticles(ticker)
.map { it.toOptional() }
.toObservable()
.startWith(None),
) { quoteCents, articlesResult ->
val stockPrice = quoteCents.toNullable()?.let {
"\$${it / 100}.${it % 100}"
}
val articles = articlesResult.toNullable() ?:
emptyList()
StockViewModel(ticker, stockPrice, articles)
}
.observeOn(uiThread)
}
This creates an uber-Observable that includes all the work that needs to be done. But again, it doesn’t kick off any work yet, so there’s nothing there to be managed.
To run the pipeline, you have to call subscribe:
disposables += apply()
.subscribe { viewModel ->
view.setModel(viewModel)
}
This subscribe call starts executing this work as an asynchronous job, and yields an object that represents that running work: a Disposable. With a Disposable, you can cancel the work when it’s time to clean up after yourself.
And… that’s about it. Once you call subscribe, the running work can be passed around and cleaned up. It can’t be waited on or composed with other work, though.
And that’s intentional. RxJava is designed around describing work, not around coordinating running work. In fact, we get to avoid thinking about coordinating running work for the most part in RxJava because that information is baked into the Observable before subscribing.
Concurrent Process Management in Coroutines
Okay, let’s repeat the same exercise for a coroutines version of this code. Instead of RxJava Singles, our stockService methods will all be suspend funs.
interface StockService {
suspend fun getQuoteCents(ticker: String): Int
suspend fun getArticles(ticker: String): List<String>
}
And instead of yielding view models through an Observable, we’ll send them to a callback passed in to a suspend fun.
suspend fun presentModels(models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
models(viewModel)
val quoteCents = stockService.getQuoteCents(ticker)
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
models(viewModel)
}
This version is shorter than the RxJava version, mostly for reasons covered in the previous post. (It also doesn’t pull in the articles yet.)
More importantly, note that calling presentModels runs the work. It doesn’t produce a description of what to do, it just does it. So if we want to do some other work in parallel inside presentModels (like fetch the articles), we don’t alter our description with an operator to pull that other work in. We imperatively start that parallel stream of work and imperatively manage it.
And how do you start some parallel stream of work? By launching a coroutine.
CoroutineScope: A Squad Of Workers
And you launch a coroutine with launch.
Knowing that launch runs a coroutine, my first stab at adding the articles code in coroutines would be something like this:
suspend fun presentModels(models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
val mutex = Mutex()
models(viewModel)
val articlesJob = launch {
val articles = stockService.getArticles(ticker)
mutex.withLock {
viewModel = viewModel.copy(articles = articles)
}
models(viewModel)
}
val quoteCents = stockService.getQuoteCents(ticker)
mutex.withLock {
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
}
models(viewModel)
articlesJob.join()
}
This is almost exactly how Kotlin’s coroutines work, with one important exception: you can’t call launch here.
launch is not a standalone function. launch is an extension method on CoroutineScope.
Why? Well, CoroutineScope is a management unit for coroutine jobs, a sort of squad of workers. Kotlin requires that every coroutine belong to some specific squad — I mean, a scope. That way, no coroutine ever gets lost: no worker can be on the payroll consuming resources without living in a squad of workers. And that means that it is always possible to stop, inspect, or wait on the work running in the application.
Great. So how do you get a CoroutineScope?
Well, there are two answers to that question. There’s how you can get a CoroutineScope, and how you should get a CoroutineScope. Let’s call the way you should get a CoroutineScope the stylish way to do things.
The stylish way to solve this problem is to use the coroutineScope function:
suspend fun presentModels(models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
val mutex = Mutex()
models(viewModel)
coroutineScope {
val articlesJob = launch {
val articles = stockService.getArticles(ticker)
mutex.withLock {
viewModel = viewModel.copy(articles = articles)
}
models(viewModel)
}
val quoteCents = stockService.getQuoteCents(ticker)
mutex.withLock {
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
}
models(viewModel)
articlesJob.join()
}
}
coroutineScope runs a block with a CoroutineScope as a receiver. launch can now be called on that CoroutineScope, so this now compiles.
But that’s not all coroutineScope does. coroutineScope also waits until all the squad’s workers are done working before continuing on (That is, every job in its CoroutineScope is done). That means that the articlesJob.join() call above is redundant:
suspend fun presentModels(models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
val mutex = Mutex()
models(viewModel)
coroutineScope {
launch {
val articles = stockService.getArticles(ticker)
mutex.withLock {
viewModel = viewModel.copy(articles = articles)
}
models(viewModel)
}
val quoteCents = stockService.getQuoteCents(ticker)
mutex.withLock {
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
}
models(viewModel)
}
}
That’s pretty neat! The code we previously wrote to hold on to our concurrent garbage and clean it up has disappeared. It’s also no longer possible to forget to write that code, or accidentally delete it.
Spreading Around The Work
That’s nice, but it does have a major consequence: presentModels won’t return until all of its work completes.
This is usually fine. You can use launch to fix this problem, by writing launch { presentModels(models) }. This doesn’t always match the API you want to present, though. Sometimes you want your method to say, “Hey, I’m going to kick off a job and leave it running for a while.” In these cases, to solve the problem you can grab a CoroutineScope from somewhere, and then launch your own coroutines into it so that whoever owns that scope can keep track of your work for you.
Again, there’s ways that you can do this, and a way that you should do it. The stylish way to solve this problem is to pass the CoroutineScope down the stack as a parameter:
fun presentModels(scope: CoroutineScope, models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
val mutex = Mutex()
models(viewModel)
scope.launch {
val articles = stockService.getArticles(ticker)
mutex.withLock {
viewModel = viewModel.copy(articles = articles)
}
models(viewModel)
}
scope.launch {
val quoteCents = stockService.getQuoteCents(ticker)
mutex.withLock {
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
}
models(viewModel)
}
}
This code launches two coroutines, but these coroutines continue running after the function returns.
(Note that it doesn’t do exactly the same thing as the previous version. It has to launch a second coroutine to grab the stock quote instead of doing this work inline. This is to abide by a minor point of style, which says that it’s bad form to define a suspend fun that also takes in a CoroutineScope as a parameter. See here for further reading on the confusions that can arise.)
This function would be run within a CoroutineScope that your caller defined somewhere, maybe like this:
coroutineScope {
presentModels(this, models)
}
…and which will be responsible for managing the workers fired up within presentModels. (Here, by waiting on them at the end of the block.)
Those are the two ways to write stylish Kotlin concurrency code: either take in a CoroutineScope as a parameter, or create one as a block with coroutineScope or another block-scoped function within a suspend fun. If you like rules, here are three rules that amount to the same thing:
- New coroutines are always launched into a
CoroutineScope. CoroutineScopeis only passed down the stack, it is never assigned to an instance variable.- Never construct a
CoroutineScopeby hand.
Those rules govern where in the call stack we use CoroutineScope. We need to add a fourth rule to govern where code runs relative to the call stack:
- Lambdas and other callbacks passed in as parameters must either complete execution before returning, or be run with a
CoroutineScopereceiver context (as inlaunch)
This rule ensures that we can never launch into an invalid CoroutineScope. For example, the coroutine here will silently fail to run because the scope created by coroutineScope would already have been torn down by the time the button is clicked:
coroutineScope {
view.setOnClickListener {
launch {
events.emit(ButtonClicked())
}
}
}
And that gives you the rules for writing structured concurrent Kotlin.
I would be remiss at this point if I didn’t link to the foundational document on the concept structured concurrency, Notes on Structured Concurrency. But let’s take a look at what structured concurrency means in practice in Kotlin.
Structured syntax
Not having to explicitly clean up all your concurrent garbage is nice. Even nicer is the way that the conventions of structured concurrency (or SC) let you use structured syntax conventions to reason about concurrency.
What do I mean by structured syntax conventions? Let’s look at the first example again to see.
suspend fun presentModels(models: (StockViewModel) -> Unit) {
var viewModel = StockViewModel(ticker, stockPrice = null, articles = emptyList())
val mutex = Mutex()
models(viewModel)
coroutineScope {
launch {
val articles = stockService.getArticles(ticker)
mutex.withLock {
viewModel = viewModel.copy(articles = articles)
}
models(viewModel)
}
val quoteCents = stockService.getQuoteCents(ticker)
mutex.withLock {
viewModel.copy(
stockPrice = "\$${quoteCents / 100}.${quoteCents % 100}"
)
}
models(viewModel)
}
}
SC conventions guarantee that every function either returns without leaving any ronin, squadless concurrent workers lying around (in the case of a suspend fun or a plain fun that doesn’t take in a CoroutineScope), or adds workers to the enclosing scope (in the case of launch). Because of this guarantee, I can use the block scoping in this code to visually see the order of operations: first my initial view model will display without articles or a quote. Next, a job is launched to fetch and display the articles. After that, a stock quote is fetched and displayed.
When the block is complete, all the work is done. And because I know what a coroutineScope block does (lets you run coroutines), I can visually see, “Oh, this coroutineScope means this block is doing some parallel decomposition of work.” The same thing goes for suspend fun as a general rule: it is a closed abstraction, and I can safely assume that all of its work has completed when it returns, even if it returns on object.
(This is why suspend fun is preferable to CoroutineScope parameter methods, by the way — it’s easier to write code in the above style with suspend fun, and if you need concurrency there’s always launch.)
This is not something that RxJava gives you. Let’s revisit the RxJava example:
fun apply(): Observable<StockViewModel> {
return Observable.combineLatest(
stockService.getQuoteCents(ticker)
.map { it.toOptional() }
.toObservable()
.startWith(None),
stockService.getArticles(ticker)
.map { it.toOptional() }
.toObservable()
.startWith(None),
) { quoteCents, articlesResult ->
val stockPrice = quoteCents.toNullable()?.let {
"\$${it / 100}.${it % 100}"
}
val articles = articlesResult.toNullable() ?: emptyList()
StockViewModel(ticker, stockPrice, articles)
}
.observeOn(uiThread)
}
It takes some study to see the first model this code emits. The structured code mechanisms that make that so easy to read in the coroutines example (“First emit the default value, then do this”) don’t exist here.
And unlike the coroutines example, it’s difficult to identify when and where the parallel decomposition happens. combineLatest is pretty clear, but it’s not the only operator that achieves that goal. In Cash App’s codebase, you will sometimes see merge used for that purpose, but it can also be used to mux out events, too, so you can’t be sure that merge means “do some work in parallel”.
Even more important, this code leaks out implementation details: the scheduler it runs on. If stockService.getQuoteCents runs on the IO scheduler, so will this Observable. So it’s not a black box abstraction, either on the page or conceptually: it leaks, and you can’t understand pieces of it without understanding the whole of it.
Cancellation & Error Handling
Another consequence of this regime is that everything can be cancelled, and exceptions always have a place to go.
You can cancel in RxJava, too, of course, but that ability comes with an important “if”: you can cancel if you have kept track of the disposable created when the work was launched. Finding the API to dispose that disposable requires some investigation, and it may not be implemented correctly.
That’s not the case in coroutines. Every coroutine has a Job, which you can use to cancel it. Every CoroutineScope has a Job, too. And all of the jobs for the coroutines launched in that scope have its Job as their parent.
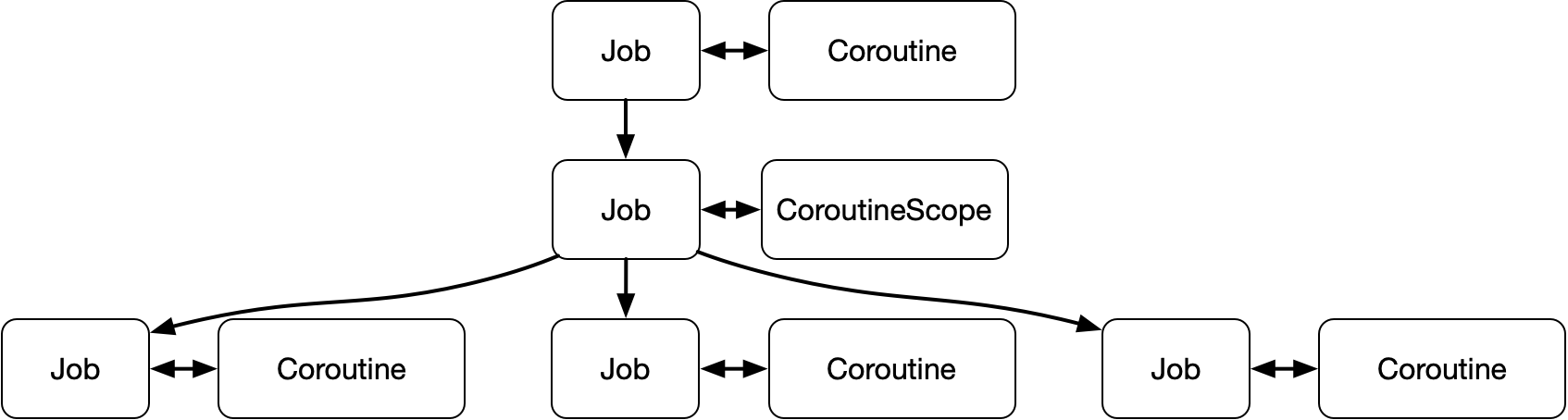
And what’s the parent Job for the CoroutineScope? The Job for the coroutine it was launched in.
So if we follow SC conventions, these jobs all form a tree. Canceling a job cancels all of its children. And if we have one node of that tree, all we need to do is cancel it and everything it was controlling will be gracefully shut down.
Even more nifty is that engineers who internalize this paradigm won’t ever need to think about this tree. They’ll only think about the code, because the indentation structure of the code on the page is the tree.
Exception handling also respects the tree: if an unhandled exception is thrown from a coroutine, the coroutine is stopped and the exception is thrown at its launch site. The same thing goes for a CoroutineScope: if it catches an exception, it will cancel all of its child coroutines and rethrow after they unwind.
The classic example of how this is used to make nifty new APIs is withTimeout. Say that I wanted to run presentModels from above, but kill it after five seconds. All I have to do is use withTimeout:
withTimeout(5000) {
presentModels(models)
}
withTimeout runs its child block in a Job. When the timeout happens, it cancels that job. Because of the cancellation tree, any child work launched within presentModels will be canceled, too. It can do as much parallel work as it wants, or none, and I never need to know: it just works.
A function could even be displaying something to the user, as in this Jetpack Compose example:
LaunchedEffect(scaffoldState.snackbarHostState) {
withTimeout(5000) {
scaffoldState.snackbarHostState.showSnackbar(
message = "Error message",
actionLabel = "Retry message"
)
}
}
…and withTimeout could cancel that work, too.
Paradigm Shift Shear
The restrictions of SC are a big change to how we manage work resources. Many common patterns are disallowed by its rules. Take the following example of some code to manage a running presenter like the examples shown earlier:
private fun <UiModel : Any> bindUi(
presenter: Presenter<UiModel>,
ui: Ui<UiModel>
): Presenter.Binding {
val binding = presenter.start(ui::setModel)
return binding
}
Our presentation framework runs the presenter by “starting” the presenter with a call to presenter.start, passing in a callback to set the view model on the view. (The Presenter interface is usually implemented by common glue code that handles the details of wiring up to RxJava, coroutines or whatever else the presenter uses.) This returns a binding; call binding.stop(), and the presenter stops running and releases all its resources.
Simple enough. Well, you can’t write it in SC.
In SC, ongoing processes are owned by a CoroutineScope, not by custom classes like binding. And CoroutineScopes aren’t passed around or held on to like objects, either — they’re only passed down the stack, so that they are visually associated with a structural block of code. That means you can’t stuff the CoroutineScope into a binding in the structured concurrency paradigm.
Instead, the presenter process must be represented either as a long-running suspend fun, like this (where presenter.present will run its business logic until the coroutine it lives in is cancelled):
private suspend fun <UiModel : Any> bindUi(
presenter: Presenter<UiModel>,
ui: Ui<UiModel>
): Unit =
presenter.presentModels(ui::setModel)
Or as a short-running fun that launches longer-running work into an existing CoroutineScope:
private fun <UiModel : Any, UiEvent : Any> CoroutineScope.bindUi(
presenter: Presenter<UiModel, UiEvent>,
ui: Ui<UiModel, UiEvent>
): Presenter.Binding<UiEvent> {
presenter.launchPresenter(this, ui::setModel)
}
}
How (And When) To Break The Rules
Unless you’re able to migrate your entire codebase over to this new paradigm at one go, you’re going to have boundary sites in between SC code and non-SC code. That means you’re going to be breaking the rules somewhere. Here are the rules you will need to break:
- Holding on to a
CoroutineScopein an instance variable - Constructing a
CoroutineScopeby hand - Calling
runBlocking(which lets you run coroutines code from a non-coroutines call site)
So how and when should you do each of these things?
runBlocking should almost never be used in production code. runBlocking is great for test code, but it’s dangerous because it blocks hard — your main thread, if that’s where you happen to be, or your coroutine dispatcher if you happen to be in a coroutine. Blocking is bad times in both locations. So treat calling runBlocking in production code like calling Looper.loop(): “never do it” might be a touch too strong, but it’s not far off the mark. (You can read more about how to shoot yourself in the foot with runBlocking here.)
Usually you’ll be doing a combination of 1 and 2. These can be used to build a bridge from legacy code designed for an RxJava-style work cancellation API to a new structured concurrent API. This means treating your CoroutineScope like a CompositeDisposable: build it, store references to jobs in it, and then tear it down when you’re done.
As mentioned above, you can’t implement the binding style we use in Cash App in SC. But that binding pattern isn’t going to change — we have a lot of non-SC code that requires a binding API. So we write binding code with CoroutineScope like this (I’ve stripped out the event handling for simplicity):
override fun bind(displayModel: (ViewModel) -> Unit): Binding {
val job = Job()
val scope = CoroutineScope(coroutineContext + job)
scope.launch(start = UNDISPATCHED) {
produceModels(displayModel)
}
return object: Binding {
override fun stop() {
job.cancel()
}
}
}
In addition to the above cases, sometimes you won’t have to do it at all! Android ViewModels have a CoroutineScope associated with their lifetime. CoroutineScope isn’t a great abstraction for “lifetime” in the way that LifecycleOwner is, but viewModelScope is an excellent entry point for structured concurrent code.
Don’t Inject CoroutineScope (as a property)
There’s a special case that you should avoid: Never inject a CoroutineScope as a property. (And never use GlobalScope, either. It’s the scope that Kotlin injects for you! Such a bad idea, avoid at all costs.) Injecting CoroutineScope can be necessary, but the CoroutineScope should always be a plain parameter confined to the stack.
To see why, consider two cases. The first one is a new component that doesn’t have any legacy work management code — no RxJava, no other kind of background task management.
In this case, the choice to inject the CoroutineScope presents itself as a great solution: the existing API can remain the same, but you get to use coroutines inside of it.
Unfortunately, this is a hack. Ask yourself, “How would I solve this in RxJava?” You would probably inject a Scheduler to give yourself a well-known place to run your Observables.
You probably wouldn’t inject a CompositeDisposable. But injecting a CoroutineScope includes both notions: it has all the machinery to enable you to run coroutines, but it also is a tool to manage their lifecycles. This isn’t a pattern we use in RxJava, and it’s not recommended in coroutines, either. (In coroutines, you would inject a CoroutineContext or CoroutineDispatcher instead of a Scheduler.)
More importantly from an SC standpoint is that it breaks the fun abstraction. Remember that in the structured concurrent paradigm, a suspend fun or fun tells you a lot about where processes are being run:
private suspend fun <UiModel : Any> bindUi(
presenter: Presenter<UiModel>,
ui: Ui<UiModel>
): Unit =
presenter.presentModels(ui::setModel)
Because we do not pass in a CoroutineScope, we know that presentModels represents a complete unit of work. If we cancel it, all of its work will be stopped. But if we allow CoroutineScope to be injected, this is no longer the case — it may be launching into an injected CoroutineScope we know nothing about. As a result we can’t be sure that other work isn’t left running when it returns, and we can’t cancel its work by canceling it.
The other case is an old component that does have some legacy work management code — e.g. RxJava Disposable code. If that’s the case, then you don’t need to inject a CoroutineScope either — you can construct one and manage it with the legacy code.
In some cases, an object unavoidably launches some work that is “owned” by the object. In those cases, it makes sense to inject the CoroutineScope that owns the work, the same as you would pass in a CoroutineScope to a function call. As long as the CoroutineScope is not marked with val or var, this is fine: the scope will be confined to the stack, which will keep work ownership structured.
Onward and upward
Now, you don’t have to write structured concurrent code — it’s possible to use these APIs without following these rules. And the new paradigm is so different that you may find yourself working into a communication gap: not everyone will pick up what you’re putting down.
But… seriously, this stuff is neat. It’s still so new that there aren’t many examples out there illustrating what a whole app can look like written in this new paradigm, but we’re lucky in the Android community to have a prominent SDK that is all in on SC: Jetpack Compose. Compose isn’t plain Kotlin, of course, but its approach towards managing long-running work abides strictly by structured concurrent principles.
And it’s the future, you know. That’s a good place to put yourself, if you can manage it.