Rx to Coroutines Concepts, Part 5: Shared Flows
Part 1, Async vs. Reactive, Part 2, Structured Concurrency, Part 2.1, Exceptions, Part 3, Deferred & Channels, Part 4, Cold Flows
In the last entry in this series, we discussed the core Flow API and how to transform one flow into another. But what about hot data sources?
Hot vs. Cold Observables
In RxJava, observables are called either “hot” or “cold”. “Cold” observables only fire up when you subscribe to them, but “hot” observables are running whether you subscribe to them or not. So for example, a PublishSubject is “hot”:
val subject = PublishSubject.create<String>()
subject.subscribe { println("Subscription 1: $it") }
subject.subscribe { println("Subscription 2: $it") }
subject.accept("Hello!")
…because subject is running whether anyone calls subscribe or not. All subscribers are the same, whether you have 0 or 50: both subscriptions here will print the same "Hello!". A “cold” observable, on the other hand, only “heats up” when you subscribe to it. That running work is specific to your subscription, too, so canceling the subscription also stops that work. Other than that, they work exactly the same.
Hot observables always communicate with a concurrent task whose scope outlives any one subscription. So when you “heat up” an observable, turning a cold one into a hot one, you create a concurrent task. And you need to be able to kill that task!
That’s what ConnectableObservable, publish(), and autoconnect() are about: ConnectableObservable adds an explicit API to start the Observable (instead of automatically starting it on subscription). autoconnect() calls that API automatically on the first subscription, and disposes the underlying subscription automatically when the last subscription is disposed.
If that system doesn’t work for you (e.g. if you want the underlying work to continue even when no one is subscribed), then you need to use something else to manually do your own Observable management. Usually that something else is a Subject or a Relay.
These APIs let you plug in to the easy-to-understand Disposable system. So that’s something. But they’re difficult for newcomers to understand, and they have the same problem discussed in part 2: it’s hard to find the owner of the actual work. Unless you use a Subject or Relay, there’s no language for monitoring or cancelling the work independently from a subscription.
Hot Shared Flows
Here’s how we think about cold and hot in coroutines:
When you call collect on a cold flow, everything (the flow and the collect) is running in a single coroutine Job, represented by the rounded rect here:

In this case, the unit of cancellation is the Job. Cancel the job, and both the running Flow and collect are cancelled as well. They’re all just code running in this coroutine.
A “hot” data source (coroutines doesn’t call them hot, but — we’ll call them that for the moment) is one where this is not true: A hot data source is driven from a Job outside the collecting Job:
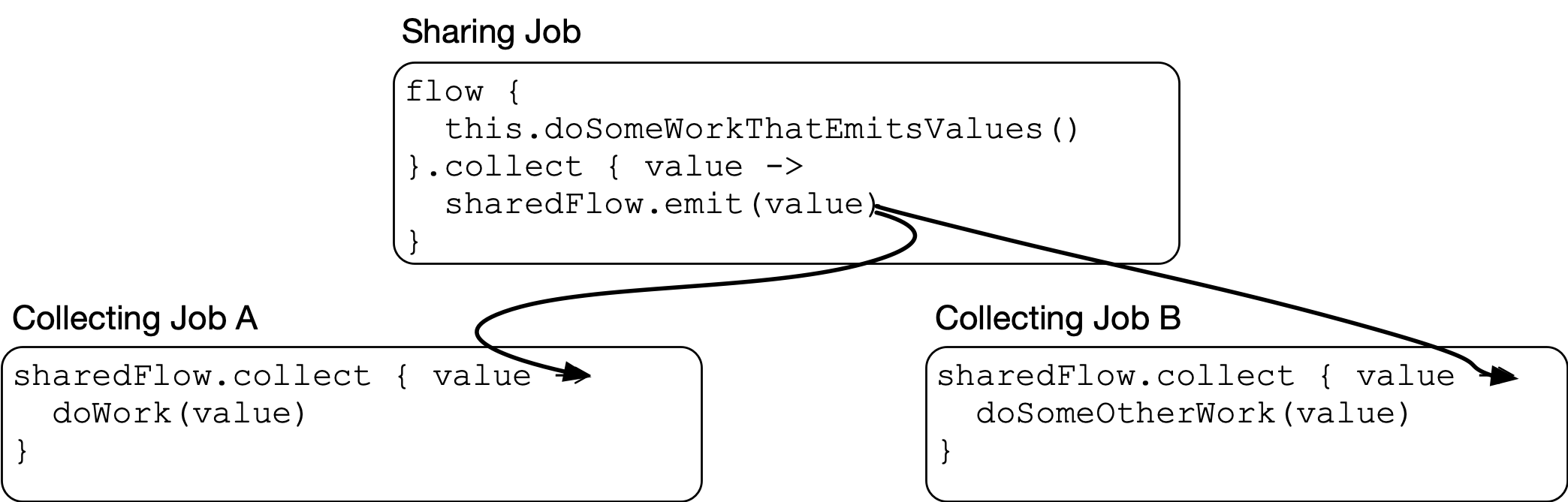
Each of these jobs can be cancelled independently of one another: You can cancel either of the jobs collecting on the data source, the job driving the hot data source, or all of them.
It doesn’t have to be a single job driving the flow, either. It could be multiple jobs sharing into the same instance:
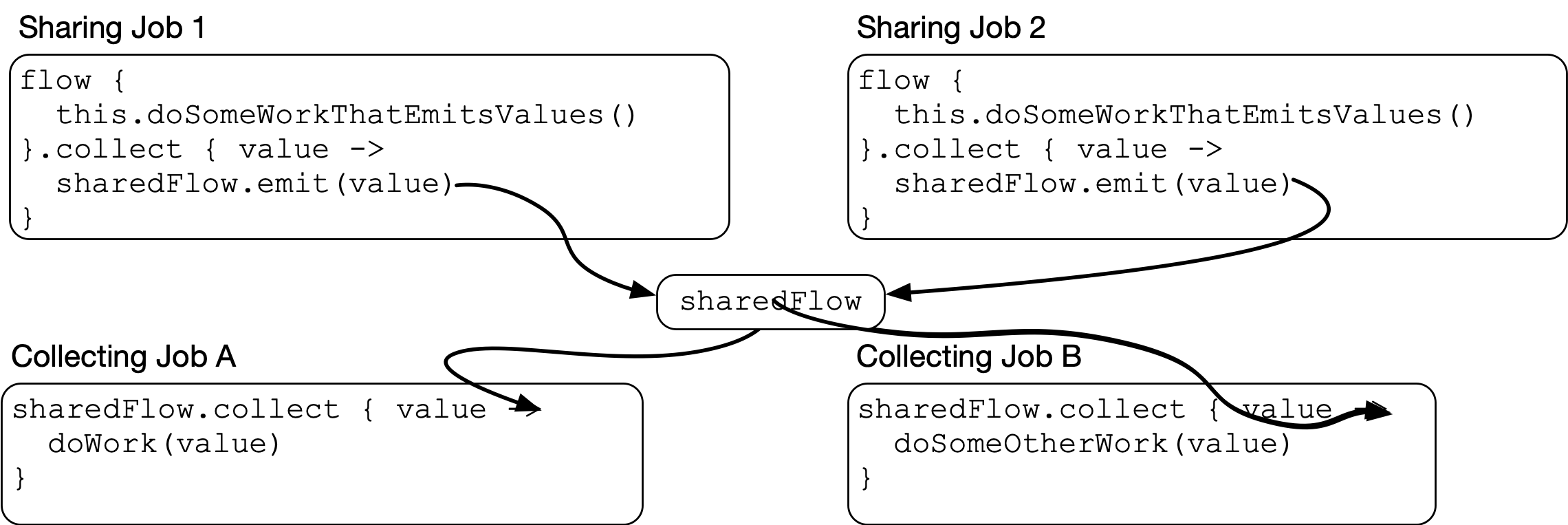
This pattern and the flows that implement it are called shared flows (since the producer jobs are “sharing” their outputs with the consumer jobs).
Shared flows (like hot observables) add a layer of complexity to thinking about flows. A shared flow isn’t one-size-fits-all:
- The sharing process isn’t always a coroutine. Can the process being shared from be suspended, or not? That is, can it call a
suspend fun? (Probably not if your sharing process is aView.) - How should historical values be handled? Should they be replayed for new collectors?
- How do callers need to read values from the shared flow? Do they require the ability to read a value without suspending?
- Who owns the sharing job? In structured concurrency, work always has an owner. Who’s it gonna be?
These tradeoffs are similar to the kinds of decisions you make when constructing a Channel, but the communication patterns are different and there are some footguns to consider. If you know what your processes are and how they’re talking to each other, that will tell you what kind of shared flow to use. But if you reach for one of these tools without thinking about what your specific scenario is, you can have problems.
So let’s start by understanding those tools: the shared flows themselves.
The Big Idea: Buffers Vs. Backpressure
Before we get into these tools, let’s talk about the big problem all these tools have to solve: sending values between jobs. Let’s look at the example from earlier to have something to think with:
This setup has the same problem we covered with Channels in part 3: Sharing Job may be running like a rabbit, and the collecting jobs may be taking their sweet time like the tortoise. So Sharing Job could emit 15 values, while the collecting jobs have only processed 1. What happens to those 14 values that the collecting jobs haven’t processed yet?
Every shared flow has a decision to make in this situation. There are only 4 options:
- Backpressure (suspend Sharing Job until the collecting jobs are ready to receive the new value)
- Enqueue (add the new value to the end of a queue)
- Replace (discard an existing value in the queue and replace it with the new value)
- Discard the new value
MutableSharedFlow, one of the two building blocks we’ll discuss here, has two methods to emit a value into the flow:
fun tryEmit(value: T): Boolean
suspend fun emit(value: T)
These two methods are identical except for one detail: emit can suspend, and tryEmit cannot. Since tryEmit can’t suspend, it may have to choose option 4. If it does that, it will return false. (This should almost always be treated as an error: guard and throw on false, unless there is a specific design intention to ignore this case.)
I’ll cover three configuration patterns that define solutions at three different extremes. They all do the same thing every time you call emit on them, but they each make a different choice about what to do. They are:
- Buffered
MutableSharedFlow - Suspending
MutableSharedFlow MutableStateFlow
These three extremes cover the majority of scenarios we care about on the client. Understand them, and the other kinds of niche behaviors you may occasionally require will make more sense, too.
Buffered MutableSharedFlow
Let’s start by talking about SharedFlow.
A SharedFlow is an implementation of the above: a flow where each collector receives values emitted by a sharer. I use SharedFlow to refer to a SharedFlow where collectors are guaranteed to receive all values that have been successfully shared to it. (This isn’t strictly true, but I need a word for it, and that’s the one I’m using.) Whatever it is, though, all SharedFlow instances (as of this writing) are implemented using MutableSharedFlow under the hood. This is a tool that allows you to manually emit items into the SharedFlow.
In Android, the most common scenario for using a MutableSharedFlow is one where the emitting job cannot suspend to wait for its recipients. View events are like this: code in a click listener on an Android View or Composable event handler cannot suspend to wait for the event to be processed. They must return immediately.
Wiring a solution for that scenario with MutableSharedFlow looks like this:
class DocumentSelectorView(context: Context) :
ContourLayout(context) {
private val _events = MutableSharedFlow<DocumentSelectorViewEvent>(
extraBufferCapacity = 50
)
val events: SharedFlow<DocumentSelectorViewEvent> = _events
private val drivingLicenseButton = Button(context).apply {
setText(R.string.select_driving_license)
}
init {
drivingLicenseButton.setOnClickListener {
if (!_events.tryEmit(DrivingLicenseClicked)) error("Buffer overflow")
}
}
...
}
This code builds a buffered SharedFlow. Calling tryEmit will attempt to put the view event on the MutableSharedFlow’s buffer:
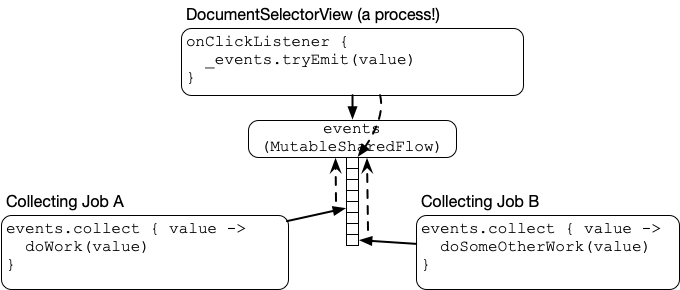
There’s the view, emitting events into a MutableSharedFlow. The shared flow queues up each event into a buffer. Each collector then has its own pointer into the buffer, which it works through as quickly as it can.
The MutableSharedFlow’s buffer size in the code above is set by the extraBufferCapacity parameter to 50. That number is arbitrary, but necessary: we need a buffer that is large enough to work for day-to-day use, but small enough that it will actually fill up in the event that something has gone horribly wrong with a collecting job.
Remember the four options discussed earlier: suspend, enqueue, replace, discard. Adding the extra buffer capacity bets on one extreme solution: add enough buffer that you expect to always expand the buffer to deliver the value.
Even with that, it’s important to write guard code that will error out when tryEmit cannot deliver a value. If you accidentally leave out the buffer and write MutableSharedFlow() — which is very easy to do! — tryEmit is almost guaranteed to fail. So make sure and check those return values.
The buffer is shared by all collectors. Each collector has a pointer that walks down the buffer as each item is read. If they finish reading everything in the buffer, they suspend to wait for a new item. When a new item is emitted into the MutableSharedFlow buffer, it gets pushed onto the top, pushing all those pointers down one item and waking up their coroutines if they were suspended.
Note that while a buffered MutableSharedFlow has a buffer like a queue or Channel, it can’t be expected to safely deliver items like a queue or a Channel will. Only active collectors will receive items sent to MutableSharedFlow. If there are no active collectors, tryEmit will happily return true: “Yes, I successfully delivered your event to no one!” It is possible to work around this issue with the replay parameter, but if you use Channel instead it can’t happen at all. This is a major reason why Channel is usually a better tool for internal wiring than MutableSharedFlow.
Suspending MutableSharedFlow
That’s one extreme: the buffer that is as large as possible. What about the other extreme: no buffer at all? If you pass in no arguments, that’s what you get:
private val _events = MutableSharedFlow<DocumentSelectorViewEvent>()
This MutableStateFlow has no buffer. And if you don’t have any buffer, tryEmit won’t do anything except wake up active collectors who are currently suspended. It will usually fail. (This is extremely surprising if you aren’t expecting it.)
This can be desirable, because emit will apply backpressure: it will wait until listeners are done before continuing. Consider another scenario: a utility that polls an endpoint periodically, publishing its results to collectors. It can be implemented as a Flow like this:
class InvestingPricePoller(
private val appService: AppService,
private val stock: Stock,
private val pollIntervalMillis: Long
) {
fun pollLatestPrice(): Flow<Price> = flow {
while (true) {
val latestPrice = appService.getPrice(stock)
emit(latestPrice)
delay(pollIntervalMillis)
}
}
}
What tool should be used to share this flow? InvestingPricePoller isn’t time sensitive like a click listener is: if its collectors are taking a long time, it can (and probably should) slow down instead of continuing to emit values into a buffer. So here, a bufferless MutableSharedFlow makes a lot of sense:
class InvestingPriceProvider(
private val poller: InvestingPricePoller,
private val stock: Stock,
coroutineScope: CoroutineScope,
) {
private val sharedFlow = MutableSharedFlow<Price>()
init {
scope.launch {
poller.pollLatestPrice().collect {
sharedFlow.emit(it)
}
}
val stockPrices: Flow<Price> = sharedFlow
}
We’ve gone from one extreme (a MutableSharedFlow that always chooses option 2, “put it on a buffer”) to the other extreme: a MutableSharedFlow that always chooses option 1, “suspend and wait for my collectors.” So our diagram now looks like this:
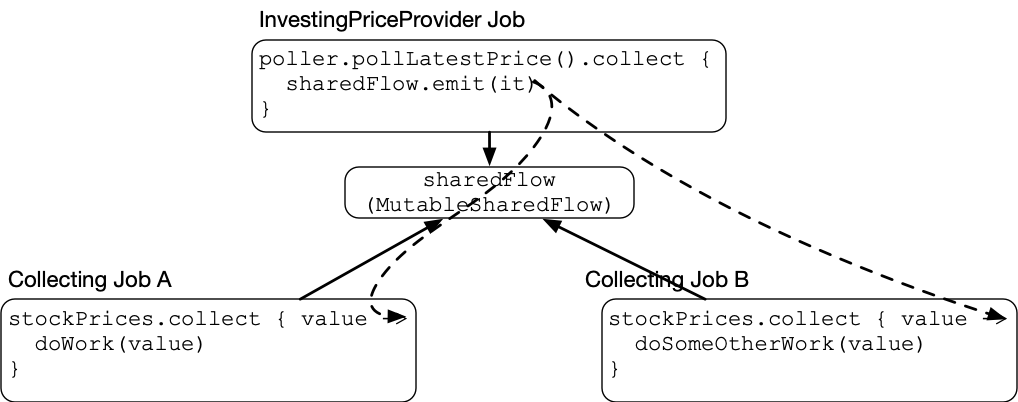
The dashed lines show how the events flow. Since there is no buffer, InvestingPriceProvider’s sharing job is directly handing values to the jobs collecting on it. When it calls emit, it will will rendezvous with each of its collectors, waiting for them to suspend at the top of their collect block. When they are ready, it wakes each one up, hands them the value, and continues on with its work.
This looks a lot like rendezvous channels so far. Unlike Channel, though, MutableSharedFlow is not guaranteed to wait for a recipient. It has the same issue we discussed at the end of the previous section on buffered shared flows: It is only sending values to active collectors. If there are no collectors, the emitted value is dropped.
(Note that, surprisingly, this tool runs fastest when there are no collectors: without collectors, there is no backpressure. See the discussion of shareIn below to see a better way to handle work like this.)
Missing Events From A SharedFlow
In fact, it is surprisingly easy to miss events from buffered and suspending SharedFlows. Take the following code for example:
coroutineScope {
val sharedFlow = MutableSharedFlow<Int>()
launch {
sharedFlow.collect {
println("Received value: $it")
}
}
flowOf(1, 2, 3, 4).collect {
sharedFlow.emit(it)
}
}
This looks like it should print out for the values 1, 2, 3, and 4, but it doesn’t. Instead, it prints out nothing. The code to emit 1, 2, 3, and 4 executes before sharedFlow.collect ever runs.
Techniques like launch(start = UNDISPATCHED) can be handy for solving this problem:
coroutineScope {
val sharedFlow = MutableStateFlow<Int>()
launch(start = UNDISPATCHED) {
sharedFlow.collect {
println("Received value: $it")
}
}
flowOf(1, 2, 3, 4).collect {
sharedFlow.emit(it)
}
}
…but a better approach is usually to use a higher level tool like shareIn to run the shared job. Scan down to see discussion of that approach. For now, let’s move on to MutableStateFlow.
MutableStateFlow
Now for our last tool: MutableStateFlow. What does it do?
Recall the 4 options for what to do with a sent message:
- Suspend
- Enqueue
- Replace
- Discard
Suspending shared flow is “always option 1”; buffered shared flow is “always option 2”.
MutableStateFlow is “always option 3”: replace an older message in the buffer with the new message.

Instead of having no buffer, or a huge buffer, MutableStateFlow has a buffer of exactly one item. This buffer is always full: when you create a MutableStateFlow, you provide a default value that goes in the buffer. That is the current state of the flow. Any time a new item is sent to the flow it overwrites this state.
MutableStateFlow is a great fit for anything stateful in an app. Which is a lot of things! For example, representing the current foreground state:
class AppForegroundStateProvider internal constructor(
private val lifecycleOwner: LifecycleOwner,
scope: CoroutineScope,
) {
private val stateFlow = MutableStateFlow(BACKGROUND)
val appForegroundState = stateFlow.asStateFlow()
init {
val lifecycle = lifecycleOwner.lifecycle
val observer = object : DefaultLifecycleObserver {
override fun onResume(owner: LifecycleOwner) {
stateFlow.value = FOREGROUND
}
override fun onPause(owner: LifecycleOwner) {
stateFlow.value = BACKGROUND
}
}
launch {
try {
lifecycle.addObserver(observer)
hang()
} finally {
lifecycle.removeObserver(observer)
}
}
}
}
Gotchas for MutableStateFlow
MutableStateFlow is the most appealing tool in the toolbox because it’s the easiest to use correctly:
- It can’t be misconfigured — there’s only one configuration
- Because it always has a state, it’s impossible to “miss” events like you can in other
SharedFlows(see “Missing Events From A SharedFlow” above) - Lots of real things in a program are stateful
- You can use
valueto assign a value to it, just like a regular variable
We’ve found a few gotchas to MutableStateFlow that are good to be aware of, however:
One is that it can be difficult to validate. Because StateFlow is designed to drop values on the floor, it is not possible to confirm all the values that were sent to it. Because of this, while StateFlow makes a lot of sense as a way to represent read-only view models coming from a presenter, it is often better to test against a non-StateFlow view of the same process. (This is one of the things that makes Molecule so nifty.) If you want more detail on this, see this blog post I wrote.
Another gotcha is around using MutableStateFlow’s value property. This is a handy API, but there is a temptation to treat it as a shared memory var. But shared memory isn’t a safe communication tool! Neither is value. Race conditions between readers and writers can result in lost data. An easy rule of thumb to remember is that a component should either read from value, or write to value, but never both.
Managing Shared Work Using shareIn
I had a whole section written here about different tactics for managing work, but I threw it all out the window. The truth is that there’s an easy pattern to remember that covers almost every situation:
- Write a cold flow to manage the work itself.
- Share it using
shareInorstateIn.
If this pattern doesn’t work, then use MutableSharedFlow or MutableStateFlow instead. Simple as that!
Now to see how to use shareIn. The following code achieves the exact same result as the more verbose InvestingPriceProvider example from earlier:
class InvestingPriceProvider(
private val poller: InvestingPricePoller,
private val stock: Stock,
coroutineScope: CoroutineScope,
) {
val stockPrices: Flow<Price> = poller.pollLatestPrice()
.shareIn(coroutineScope, SharingStarted.Eagerly)
}
shareIn will construct a MutableSharedFlow, collect on pollLatestPrice(), and emit the results into the resulting shared flow. SharingStarted.Eagerly tells shareIn to start collecting on the underlying flow right away. It can also collect Lazily, waiting until the first collector to come along before beginning.
There’s one more option, though, that is a perfect fit for our scenario. Since we want to avoid polling too frequently, it would be best if we only polled while we have active collectors. It’s possible to build that by using MutableSharedFlow.subscriptionCount, but it’s easier to use WhileSubscribed:
val stockPrices: Flow<Price> = poller.pollLatestPrice()
.shareIn(coroutineScope, SharingStarted.WhileSubscribed())
By using WhileSubscribed, polling will start when collect is first called, and stop when there are no active collectors left.
Even with that, though, WhileSubscribed will continue to run and wait for new subscribers. To clean it up, its coroutine (which we have no direct access to) must be explicitly cancelled. To do that, you must launch a new coroutine so that you have something to cancel:
coroutineScope {
launch {
val stockPrices = poller.pollLatestPrice()
.shareIn(this, SharingStarted.WhileSubscribed())
coroutineScope {
// ... do some parallel work
}
cancel()
}
}
As soon as the work inside the inner coroutineScope finishes, cancel() is called to tear down the coroutine created by launch. Without the launch, the CancellationException thrown by cancel() would tear down the outer coroutine as well, preventing any code after the outer coroutineScope from running.
Shared Flows: Aren’t They Neat
Well I think that should cover everything there is to know about shared flows. I’m sure I’ll find out more later, but here are the key takeaways to remember:
- Shared flows are like hot observables
- Every shared flow is driven by some concurrent work — either a coroutine
Jobrunning somewhere, or a non-structured concurrent framework like the Android View system - Check your
tryEmitreturn values - Know when to buffer
shareInis pretty neat