Rx to Coroutines Concepts, Part 3: Deferred & Channels
Part 1, Async vs. Reactive, Part 2, Structured Concurrency, Part 2.1, Exceptions, Part 4, Cold Flows, Part 5, Shared Flows
(Note: In researching this post, I’ve found an error in my guidelines in writing Structured Concurrent Kotlin code from post 2 in this series. Tl;dr is that it is okay to inject CoroutineScope, provided that it is not assigned to a property. You can find more details on that correction there. This post will reflect the new guidelines.)
We’ve talked about the differences between RxJava and coroutines in how async work is accomplished, and how parallel work is owned in coroutines’ structured concurrency model.
The next step is a pretty big one: how do concurrent processes talk to one another? Take a chat service as an example:
A presenter displaying chat to the customer is, on its own, an independent process displaying the chat interface. But the service communicating to the back end chat server may also be an independent process: it can poll for new messages, or queue up messages to ensure that they are delivered reliably.
Coroutines has a richer language than RxJava for describing how processes talk to one another, so it will take a few posts to cover the topic in detail.
RxJava Comms Tools
In RxJava, everything (to a first approximation) is one of four things: an Observable, a Single, a Maybe, or a Completable.
This includes all of RxJava’s communications tools: they’re implementations of the shared RxJava interfaces that have shareable semantics or can be fed from multiple locations at the same time. They tend to be described as tools for “creating hot observables” or “warming up an observable”.
Let’s consider an oversimplified ChatService from above as it might be implemented with an RxJava API. It should have a public API that allows consumers to try and send new chat messages, observe the current state of the chat (a list of messages), and asynchronously retrieve a populated session for the chat:
interface ChatService {
val session: Single<ChatSession>
val chatMessages: Observable<List<ChatMessage>>
fun sendMessage(message: SendChatMessageRequest)
}
This API fits a pattern we’ve seen repeatedly in Cash App: several presenters are using the same business logic, and also need to share data. Here, that shared data is a session (which should be created only once) and the current list of chat messages (which changes over time, but should look the same for everyone). Any screen should be able to call sendMessage and have the result show up in any other screen.
Here’s one way of building that in RxJava:
class RealChatService(
val chatAppService: ChatAppService,
): ChatService {
override val session = chatAppService.startSession().cache()
private val sendRequests = PublishSubject.create<SendChatMessageRequest>()
private val _chatMessages = PublishSubject.create<List<ChatMessage>>()
override val chatMessages: Observable<List<ChatMessage>>
= _chatMessages
init {
session.flatMapObservable { session ->
sendRequests
.flatMapSingle { chatAppService.sendChatMessage(session, it) }
.scan(session.initialMessages) { messages, it ->
when (it) {
is Success -> {
messages.mergeWith(it.response.updatedMessages)
}
else -> messages
}
}
}
.subscribe(_chatMessages)
}
override fun sendMessage(message: SendChatMessageRequest) {
sendRequests.onNext(message)
}
}
Inside init, a subscription is started that processes message requests. It processes a PublishSubject of SendChatMessageRequest. Every SendChatMessageRequest is sent to the server, and if it is successful, RealChatService merges the newly updated list of messages into its own working list.
PublishSubject is used to connect the inputs (calls to sendMessage) to the running subscription because — well, that’s how things work in RxJava is why. In RxJava, sequences of items are represented by Observable, and Observable can always be subscribed by as many listeners as want to observe it. In this application, it operates as a queue, but nothing about the implementation enforces that.
It also has a single ChatSession, which is created only one time. By using the cache() operator, one initial setup call can be safely shared by every consumer that needs it.
Coroutines: Different Tools For Different Jobs
If we go over to coroutines land, things look…different.
In RxJava, the type of API you used was determined by how many objects were flowing through it: many objects, just one, maybe one, or none.
That’s not the case in coroutines. In coroutines, a different type of job often means using a different tool with a different API.
Deferred
Deferred is the simplest example. In RxJava, our shared ChatSession was exposed as a Single on the public API, and sharing one call to multiple listeners was accomplished by calling cache() on an underlying Single:
interface ChatService {
val session: Single<ChatSession>
...
}
In coroutines, the analogue to a Single is a suspend fun:
interface ChatService {
suspend fun session(): ChatSession
...
}
But what sort of things suspend? Practically anything can! Many simple coroutines tools operate by simply suspending until they’re ready to continue. Including (if you’ll recall from part 2.1) waiting on a Job.
And it just so happens that some Jobs yield values:
class RealChatService(
scope: CoroutineScope,
val chatAppService: ChatAppService,
): ChatService {
private val _session: Deferred<ChatSession> = scope.async {
chatAppService.startSession()
}
override suspend fun session() = _session.await()
...
}
This is what a Deferred is: it’s a Job that can produce a value. Invoking async starts a coroutine, and (just like launch) returns a Job, but it also returns a little something extra: an API to wait for a value emitted by that job. If the async coroutine throws an exception instead of producing the value, Deferred.await() will throw, too.
This implementation isn’t precisely the same as calling cache() on a Single. That may be inevitable: there really is no tool in RxJava that does exactly what Deferred does. Deferred is a communications tool: it allows a sending coroutine to efficiently communicate a result with one or more receiving coroutines.
This communication is efficient, too: If the receiver calls await() before the result is ready, the receiver is suspended and sent off to a parking lot on the side by the scheduler. When the sending coroutine finally produces the result, any receiving coroutines are immediately pulled out of the suspension parking lot and sent to the dispatcher to run again with that data. Unless there are a lot of coroutines running, this effectively happens immediately.
It can sometimes be handy to have a Deferred that stands by itself, without an associated coroutine. (For example, you might have one coroutine that emits several work products at different points in its lifetime.) This is what a CompletableDeferred is:
class RealChatService(
scope: CoroutineScope,
val chatAppService: ChatAppService,
): ChatService {
private val _session = CompletableDeferred<ChatSession>()
override suspend fun session() = _session.await()
init {
scope.launch {
val session = chatAppService.startSession()
_session.complete(session)
}
}
...
This code does the same thing, except the Deferred is handled from the outside. (Note that we left out error handling: what happens if startSession() throws?)
Unlike with async, it is technically possible to call complete multiple times, but it doesn’t make much difference: subsequent calls have no effect.
Channel
Channel does a similar piece of work in coroutines world, but while a Deferred will only suspend one time, to produce a single value:
// Suspends, if the job is not done yet
val value1 = deferred.await()
// Will return the same value as value1 immediately
val value2 = deferred.await()
A Channel can suspend multiple times:
// Suspends, if a value is not ready in the channel yet
val value1 = channel.receive()
// Same thing
val value2 = channel.receive()
Since it can produce multiple values over time, Channel acts like a queue. So it’s a perfect match for the job done by PublishRelay above:
class RealChatService(
scope: CoroutineScope,
val chatAppService: ChatAppService,
): ChatService {
...
private val sendRequests = Channel<SendChatMessageRequest>()
override suspend fun sendMessage(message: SendChatMessageRequest) {
sendRequests.send(message)
}
}
Backpressure vs Buffers
There are two notable differences between this code and the RxJava code using PublishSubject. The first is that Channel really does act like a queue: for each item sent to it with send, only one recipient will receive it with receive. This is how we were actually using PublishSubject of course, but Channel matches our intention better.
The other one is that this example uses backpressure. Implicitly, PublishSubject has a queue inside for each subscriber: each published item is popped onto the queue, and the subscriber receives it when it wakes up.
This is not the case for a Channel(). A Channel constructed with no parameters has no buffer; there’s nowhere for the item in send to go. So when send is called, the caller will suspend until a receiver is ready to pick up the item. (This is why a Channel constructed with no parameters is called a rendezvous channel: it waits to rendezvous with its receiver, handing over the item directly.)
Anytime two concurrent components communicate with one another, one of these two options must be chosen: either backpressure, or buffering.
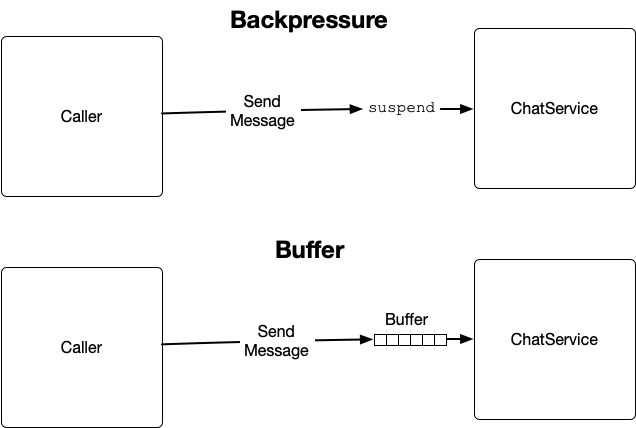
And that’s because when you get right down to it, if component A is trying to send to component B, A might be sending faster than B can keep up with. You can either slow A down so that B can catch up (backpressure), or you can save up the things A is sending until B can get to them (buffering). RxJava3 and Kotlin coroutines both support these two techniques, but the notion of backpressure is baked right into coroutines with suspend.
To buffer instead, pass in a buffer size when constructing a Channel. A PublishSubject will always buffer; conceptually, its buffer size is unlimited. Passing in a buffer size of UNLIMITED when building a Channel will do the same thing in coroutines:
private val sendRequests = Channel<SendChatMessageRequest>(UNLIMITED)
override fun sendMessage(message: SendChatMessageRequest) {
sendRequests.trySend(message)
}
trySend is like send, but it will not suspend. Instead, it will attempt to send, and fail if it can’t buffer the sent object. With a rendezvous channel, trySend will always fail; with an UNLIMITED channel, trySend will always succeed. (Until you run out of memory, at least.)
Consuming a channel is a matter of calling receive to receive a single item, or using in to iterate over the channel:
init {
scope.launch {
val session = session()
var messages = session.initialMessages
for (sendRequest in sendRequests) {
val response = chatAppService.sendChatMessage(session, sendRequest)
messages = when (response) {
is Success -> {
messages.mergeWith(response.response.updatedMessages)
}
else -> messages
}
}
}
}
(There is also a tryReceive, but that’s useful less often than trySend. tryReceive will not suspend, which means that it may not yield a value. And getting a value is exactly what you want when you try to receive a value.)
Channel As Concurrency Tool
When you get right down to it, Channel is a queue that you can close that supports backpressure and some other synchronization superpowers. It is extremely useful and a foundational tool for any coroutines-fluent engineer.
For almost all public APIs, though, it’s a bad choice. Most public APIs need to expose the idea of “an asynchronous stream of objects.” But Channel is poorly suited for this:
- Since it’s a queue, each item that goes in will only go to one consumer. Two callers pulling from the same
Channelwill each receive a different set of items. - Since
Channeldoesn’t have a baked in notion of a “subscripton” like RxJava does, it’s not easy to make a new implementation of theChannelAPI that acts more likePublishSubject.
As an API, Channel can make sense if you want to convey ownership: the signature fun processEvents(events: ReceiveChannel<Event>) tells you, “Hey, these events are yours, not anyone else’s.” But this is a rare situation. This is why Flow is so much more common: for these other scenarios, Flow is a perfect fit.
Channel shines as an implementation tool. If you dive under the hood of various RxJava operators, you will often find difficult to understand code that relies on Java concurrency primitives like AtomicReference and synchronized. But under the hood of most fancy Flow operators, you’ll find the simple Channel doing the heavy lifting in a short, easy-to-read method. We’ll show some examples of that in a later post in this series.
Buffering behavior
Additional fantastic powers have been given to the Channel. Let us discuss what they are!
The first one is the ability to change what happens when the channel runs out of buffer space. Here’s the interesting parts of the Channel constructor function:
public fun <E> Channel(
capacity: Int = 0,
onBufferOverflow: BufferOverflow = BufferOverflow.SUSPEND,
): Channel<E>
onBufferOverflow controls what happens when you call send on the Channel when its buffer is full. The default we’ve already discussed: suspend until there’s room in the buffer.
The two other options for BufferOverflow: DROP_OLDEST, and DROP_LATEST, make it so that instead of suspending, some item is discarded from the buffer to make room for the new one: either the first item, or the last item. These channels will never suspend: send is equivalent to trySend.
The most common use of these dropping buffer behaviors is to use a conflated channel: Channel(CONFLATED). The CONFLATED constant is a shortcut for creating a channel with a capacity of 1, with onBufferOverflow set to DROP_OLDEST. This is handy for cases where you want to wait for a result, but only the most recent result:
coroutineScope {
val results = Channel<ProfileResult>(CONFLATED)
val profileJobs = listOf(
launch { results.send(profileService.get()) },
launch { results.send(backupProfileService.get()) },
}
val session = startSession()
val result = results.receive()
profileJobs.forEach { it.cancel() }
showProfile(session, result)
}
If both profileService and backupProfileService return a result before startSession() finishes running, the results channel will still only have one ProfileResult in it: the most recent one.
Select
The other superpower granted to Channel is the select tool. (This API is experimental so, fair warning: could be stale by the time you read this!)
select actually isn’t specific to channels. It can be used with a variety of different coroutines tools. See, the ReceiveChannel interface (which Channel implements) has the following strange val on it:
val onReceiveCatching: SelectClause1<ChannelResult<E>>
What on earth is a SelectClause1? You can see a similar val on the Deferred interface:
val onAwait: SelectClause1<T>
These values are all used in the select function. By passing in these SelectClause values, the select function can take in a few different suspend calls, suspend on all of them, and only return the first one that resolves.
This is actually an even better way to implement the backup service example above:
coroutineScope {
val results = Channel<ProfileResult>(CONFLATED)
val profileServiceResult = async { profileService.get() }
val backupResult = async { backupProfileService.get() }
val firstResult = select<ProfileResult> {
profileServiceresult.onAwait { it }
backupResult.onAwait { it }
}
listOf(profileServiceResult, backupResult).forEach { it.cancel() }
val session = startSession()
showProfile(session, result)
}
ReceiveChannel.onReceive works the same way, even side by side with Deferred.onAwait if you like.
Almost There
There’s one last piece that we need to complete the implementation above: the public API. For that, we need to expose an API that does the same thing Observable does: subscribe to an asynchronous stream of values.
With that, we’ve reached the limits of the foundational coroutines tools that don’t have a similar API to something in RxJava. I’ve shown them first because they’re really the meat and potatoes of coroutines: they’re architecturally better, easier to read, and potentially more efficient than their equivalents in RxJava:
Channelis simpler and more flexible than aPublishSubjector similar tool used for the same purposesuspendcode makes logic more clear than logic chained through successive RxJava operator callsasyncandlaunchblocks make it clear when concurrent logic is being introduced (versusSingleandSingle.cache(), which don’t always do this)DeferredandChannelmake it clear how and when plain old linear Kotlin logic is coordinating with other plain old linear Kotlin logic- Structured concurrent code makes concurrency easier to reason about and abstract over
In the next post, we’ll see that Flow builds on top of all the tools above to expose a common API for a subscribable asynchronous stream of values. These tools are the foundation of writing beautiful code in Flow. For now, though, I’ll leave you with the additional code that completes the example from this post (which uses a shared flow):
/** Overrides val chatMessages: Flow<List<ChatMessage>> */
override val chatMessages = MutableSharedFlow<List<ChatMessage>>(
replay = 1
)
init {
scope.launch {
val session = session()
var messages = session.initialMessages
for (sendRequest in sendRequests) {
val response = chatAppService.sendChatMessage(session, sendRequest)
messages = when (response) {
is Success -> {
messages.mergeWith(response.response.updatedMessages)
}
else -> messages
}
chatMessages.emit(messages)
}
}
}