Obsolete code is slowing you down
As engineering teams, an important measure of our effectiveness is how quickly we are able to build. If we can realize an idea more quickly, we can do more. While it may be possible to just have many more people building, there are limits to effective team size when working on the same thing. At Cash App, we prefer to be lean and to enable each person to have a big impact. Doing so helps us ship, and it makes every engineer feel more impactful.
In this post I want to focus on practices that get more velocity out of the codebase.
Evolving models to match reality
At Cash App we like to start small and iterate. The product evolves rapidly, and predicting the future correctly is hard. Building speculatively often means overbuilding, and that extra complexity can slow us down now while not necessarily helping in the future.
A consequence is that our initial assumptions can conflict with the new world we’re building. The easy thing is to just layer the new understanding on top of the existing one, but this makes the code and data models increasingly confusing to anyone who works with the system — including yourself in two months’ time.
What to do instead? Backfill! You introduce the new structure, and then do the work of migrating the old structure to the new structure, then you delete the old structure. We’re on the third iteration of a backfilling infrastructure to make this kind of thing easier, in the form of a service that tracks backfill state and calls templated backfill code. Cash App runs hundreds of backfills a year.
Evolving models safely
You need to be careful when changing data models. If you have a bad deploy, you can usually roll back to stop the errors. If your deploy wrote bad data, however, rolling back may not help.
It’s easy to have a simplistic picture in which deploys go from old code to new code, but in fact we do canary deploys and gradual rollouts in which new code runs side by side with old code. And in between the two is the database — alongside caches, other services, and anywhere else the service reads from and writes to. So we need to be mindful of data compatibility.
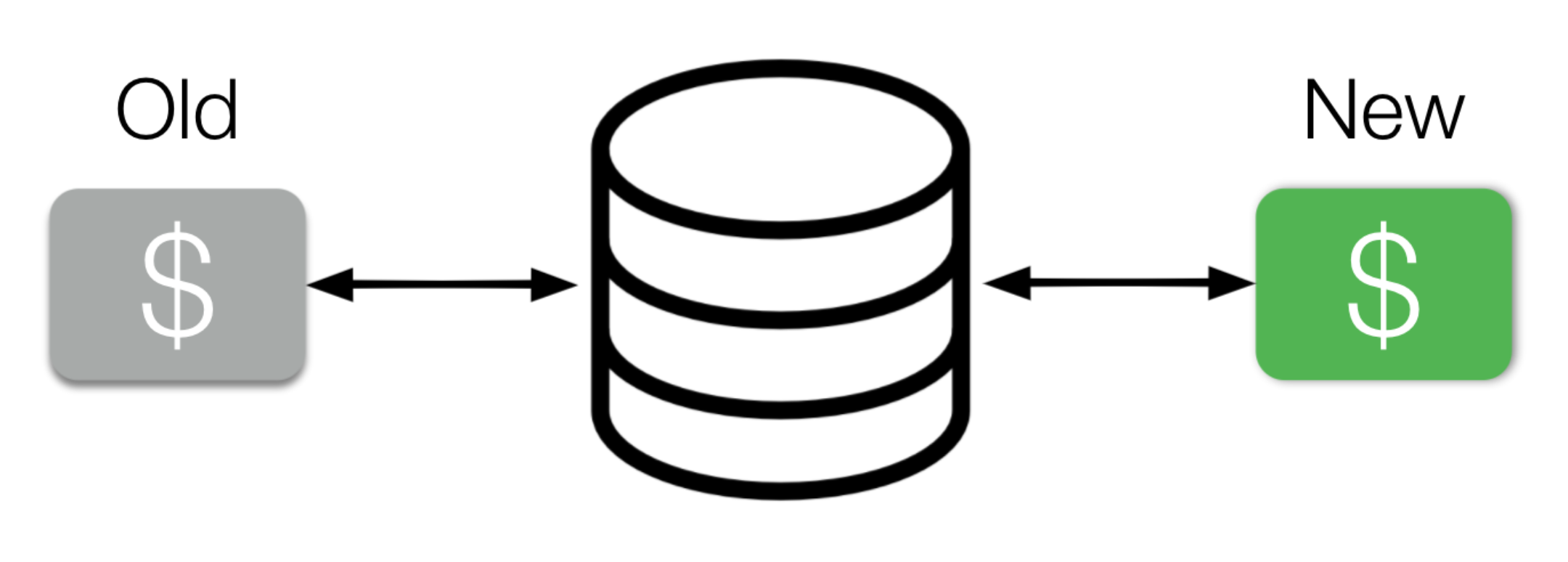
Backward compatibility is usually easier to think about: new code needs to be able to deal with what the old code produces, i.e. the existing data. Forward compatibility requires us to make sure the old code can handle data from the future. We just need to consider this when building that future.
A new enum value is a common scenario with a forward compatibility problem, particularly if your code follows these steps:
- Shapes.CIRCLE not defined
- Shapes.CIRCLE defined and written
If the new code writes the new enum value and the old code reads it, it will fail to parse it and be sad. So what we want to do instead is:
- Shapes.CIRCLE not defined
- Shapes.CIRCLE defined (can be read), but never written.
- Shapes.CIRCLE is written too.
Steps 2 and 3 need to be their own deploys/releases, i.e. steps 1 and 3 cannot overlap. An alternative if you’re impatient is to turn on writes with a feature flag — you just need to make sure to wait long enough that the deploy isn’t going to be rolled back, and then of course you’ll need to not forget to delete the feature flag.
Here’s another example, for dropping a database column:
- Column mapped in ORM, always assumed to exist, column is not nullable in the database
- Column is made nullable
- Column no longer read (can deal with it being null)
- Column no longer mapped in ORM, no longer written
- Column dropped from database
These formulas aren’t hard if you make checking for data compatibility a habit or a checklist item.
Reducing code complexity
 (Photo: Choo Yut Shing)
(Photo: Choo Yut Shing)
Software systems grow in interesting ways. As more features and dimensions are added, the complexity adds challenges to building within the system and onboarding engineers new to it. It also means there’s a lot more code that potentially needs to be changed when we need to iterate on the data models, abstractions, or technology.
It’s good to delete obsolete code! Besides the above complexity, overgrown paths in the code present potential security risks, and outdated code can hide bugs and cause incidents — all of which of course slow us down. Deleting code simplifies our systems, helps us move faster, increases safety, and is also just very satisfying.
Delete unused code. A good place to start is if you’re poking around at a system, if there’s unreferenced code or commented out code — get rid of it. (It’ll be there in version control if you need it.)
Delete forgotten code. There can be whole internal API calls that are fully functional but no longer called by any clients. Or it might be a parameter that’s always the same, or a branch that can’t be hit. This could be instrumented, but it’s a good idea when you’re working in a system or looking at adjacent call sites to pay attention to the WTFs — why is this thing here, or why are there three different ways to do X. Sometimes it’s just dead code that you can clean up, and you can formulate and test a hypothesis through existing or new logs or metrics. Oh, and remember backfills? Delete those too.
Delete feature flags. Feature flags are great — they let us safely iterate on new functionality, and decouple behavior changes from deploys. But there’s a couple of dangers. One is turning on feature flags in production when they’re not turned on in tests. For flags that potentially have effects on various parts of the system, the test suite is a much lower stakes way to discover problems. Generally, once a feature is near complete, it’s better to default flags in the tests to be in the new world.
Once the change is out, we have two code paths but one of them is dead. People making changes have to update both paths, slowing them down. At some point the flag becomes dangerous when the old logic becomes so surprising that the flag value accidentally being reverted would mean an outage. Delete it!
Drop old clients. Much of our code supports internal clients and services, and much of that is for our iOS and Android apps. We roll out new features with differential logic for new app versions with a new way of doing things and old ones that don’t. In part so that we don’t need to carry server support for years worth of outdated APIs, we have a mechanism to deprecate and eventually drop old client versions. And then? You can clean up the old stuff.
What gives us the confidence to go through with refactoring and cleanup? The most important thing is we have quite comprehensive automated tests. If you don’t have tests, then you really do have legacy code and you’ll probably need to add them before you’ll be comfortable updating the code much. But in addition to tests, code archaeology helps.
Systems evolve, code moves around, the context changes, and the code may no longer reflect reality. Try to figure out how it got to be the way it is. The code naming and comments may be unreliable but they are a guide, as are people who have worked with the code before. There is support for stepping back through history in GitHub and with Jetbrains IDEs, which can surface some of the original context for a piece of code. And it can help focus to come up with a (perhaps naive) hypothesis that you test through that investigation, as well as through instrumentation.
Delete features. This is an effective way to reduce complexity and of course has the most nuance. A good motivation is code with a high maintenance burden or a large complexity cost that slows down the team. Engineers may know this, but product managers won’t if no one has explained the issue. Here it’s important to understand both the cost of the code as well as the utility of the feature — and to be able to help quantify it. You may be able to convince people that the feature is obsolete, or you’ll discover its actual importance in the product.
There’s gradations to feature deletion or unshipping. The easiest is we just turn it off, which sometimes works. Other times we plan a sunsetting experience over a period of time, as we did when we got rid of our original email-initiated payments. And sometimes we organize a whole new team to build lighter replacement features that let us delete a costly existing feature.
Build faster
We build faster by evolving the data model and deleting obsolete code and features. And we do that safely by defaulting feature flags on in tests, and by being mindful of data compatibility.