Request Affinity with Istio
Behind the scenes, much of Cash App consists of a set of distributed services running on a Kubernetes cluster in AWS. Our engineering team started moving services to Kubernetes over the past few years and in concert with that we recently began rolling out Istio as a service mesh for service-to-service communication. In this post, I’ll focus on how the ability to deterministically load balance requests with Istio helped us to greatly improve performance and stability for one of our unusual services.
Service meshes take on many aspects of how services discover and talk to other services. One of the appealing features is control over how requests are load balanced across service pods. Prior to using Istio, each service had a dedicated Elastic Load Balancer (ELB) to distribute traffic to its pods. With Istio, the responsibility of load balancing requests is pushed to each downstream client pod, removing load balancers from the flow of traffic and adding the ability to configure richer load balancing behavior.
The problem
We run a Kafka cluster in AWS for asynchronous event pub/sub. To bridge a legacy system we have a Kotlin service, evently-cloud, that sits between the legacy service and Kafka. This service exposes APIs to fetch events for Kafka topics at certain offsets.
Kafka clients take seconds to initialize and seek to specific offsets in a Kafka topic. Since we don’t want API calls to also take seconds, evently-cloud aggressively caches Kafka clients for each consumer of a topic. In order for this cache to be used effectively, requests for a topic and consumer should always be handled by the same pod. In other words, requests have affinity for a specific pod based on the request’s Kafka topic. The affinity between pods and topics was originally handled by code in the evently-cloud service. When a request arrives, evently-cloud uses consistent hashing to determine which pod owns the request’s topic, then calls that other pod to fetch the data to return. Since evently-cloud has many pods, most requests to it end up being handled by two different pods:
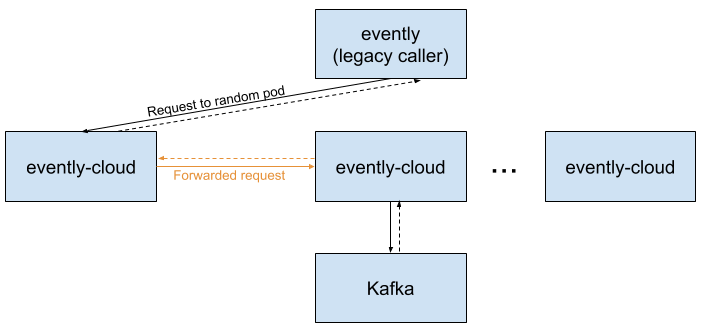
In practice, this caused a range of stability issues, the main one being a susceptibility to cascading failures. Since the chances of a request initially hitting the right pod are small, most pods waste significant resources forwarding requests. We found performance tuning for this to be consistently difficult. Worse, a pod becoming degraded can cause the pods calling it to also back up and eventually become degraded too. Evently-cloud was fragile and scary to operate as a result of these conditions.
The fix: move request affinity into Istio
Istio configures how clients load balance requests to other services, and allows configuring different policies for load balancing. By default Istio uses round robin load balancing to evenly spread requests across pods but this can be configured per service.
When migrating evently-cloud to use Istio, we instead configured it so that clients use a deterministic consistent hash load balancing algorithm. With this configuration, clients sets an HTTP header which is then hashed to determine which pod will receive the request. Like before, pod affinity is based on a consistent hash algorithm, but hashing is now done in infrastructure instead of application code.
Much of Istio configuration is done by defining custom resources in Kubernetes. Istio has the concept of a “destination rule” to specify various behaviors when calling a specific service. To configure the behavior we wanted, we applied the following YAML to our Kubernetes cluster:
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: evently-cloud-deterministic-routing
namespace: evently-cloud
spec:
host: evently-cloud.evently-cloud.svc.cluster.local
exportTo: ['*']
trafficPolicy:
loadBalancer:
consistentHash:
httpHeaderName: 'x-evently-topic-key'
That’s all it took on the Istio side. We needed no application code changes, or even restarts, to apply this policy.
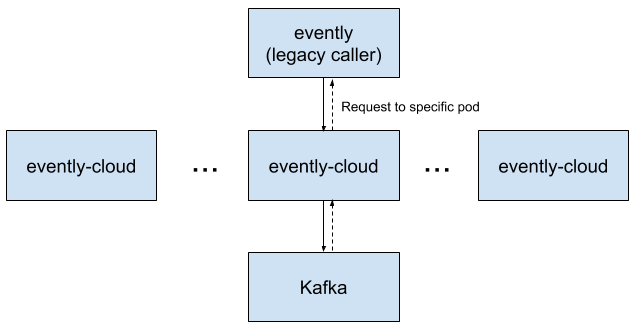
Since Istio now deterministically routes requests, we also updated evently-cloud to not forward to a peer if the new header is set. This had the added benefit of removing some of the more complicated code. To safely roll this out, we added various feature flags in evently-cloud and its callers to allow the old request forwarding behavior if needed.
With request forwarding removed, a hop is removed from most requests:
Outcome
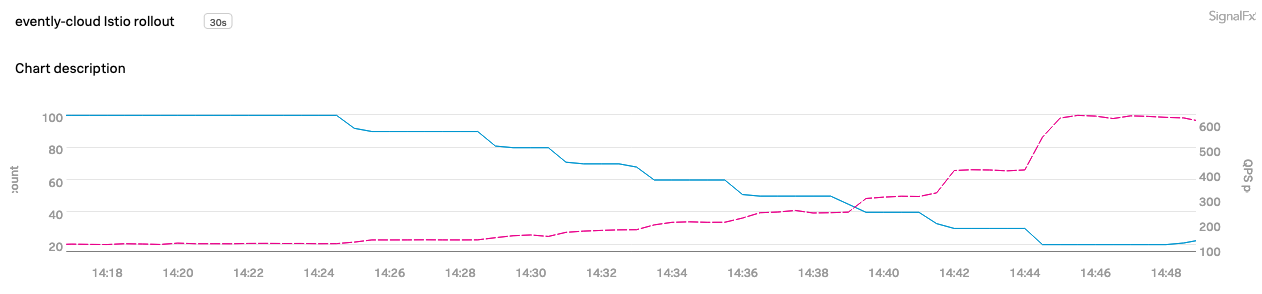
We saw a great improvement in both performance and stability after this change.
Without the overhead of request forwarding, we were able to reduce the number of evently-cloud pods running from 100 to 15 without impacting our SLA. In the chart above, the blue line shows us manually decreasing the number of pods in small increments, which in turn increases the number of requests handled by each pod (the pink line).
Aside from better resource utilization, pod failures are now more isolated. Degraded pods only affect the callers for that pod’s dedicated topic, no longer degrading the entire evently-cloud service.
This deterministic routing covered in this post is just one example of benefits we’ve found in using Istio. Other highlights include much more even load balancing of requests across service pods in general, TLS termination in Istio Envoy sidecars that is more performant than the default JVM configuration, offloading of mutual TLS certificate management to Istio.
I hope you’ve enjoyed learning about Istio and how it maps to certain problems. If you like working on infrastructure problems, we’re hiring at Cash App!
Acknowledgements: My colleague Ryan Hall helped investigate and roll out these changes, and Jan Zantinge has been my collaborator in the larger Istio migration project.