Project Teleport: Cost-Effective and Scalable Kafka Data Processing at Block
Introduction
In February 2022, Block acquired Australian fintech Afterpay. This acquisition necessitated the convergence of Afterpay’s Data Lake, originally hosted in the Sydney cloud region, into the Block ecosystem based in the US regions. Project “Teleport”, as the name suggests, was developed by the Afterpay data team to tackle this large-scale, cross-region data processing challenge. Built using Delta Lake and Spark on Databricks, Teleport ensures efficient, reliable, and lossless inter-region data transfer, utilizing object storage for transient data.
By incorporating a nuanced checkpoint migration technique, we performed seamless migration of legacy pipelines without reprocessing historical data. With Teleport, Afterpay data team reduced cloud egress costs by USD 540,000/annum, with zero impact on downstream user experience.
History of Kafka data archival and ingestion at Afterpay
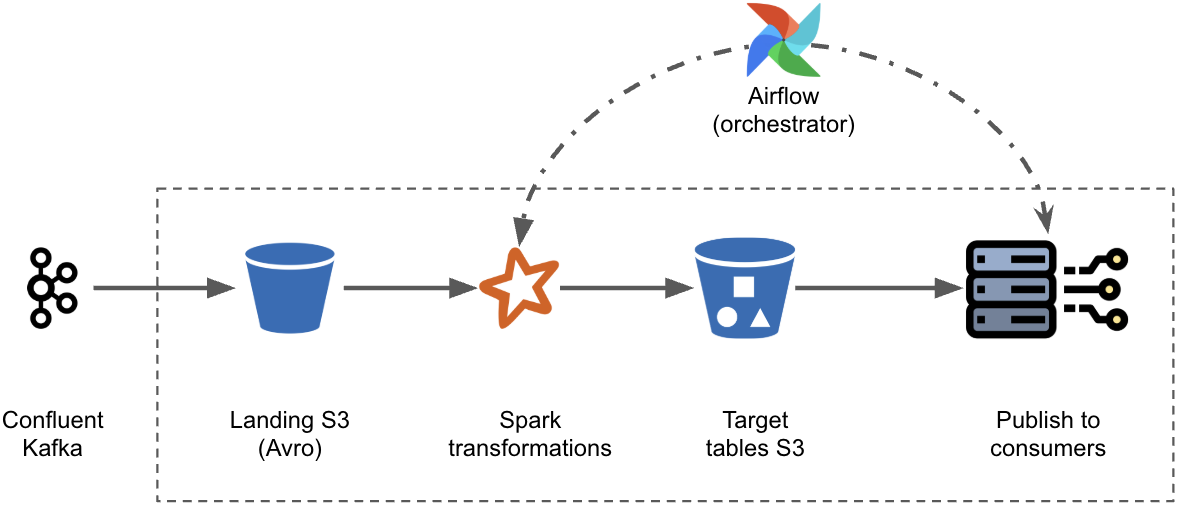
Afterpay archives Kafka data using Confluent Sink Connectors that land hourly topic records as Avro files in the Sydney region (APSE2) of S3. Before Teleport, Spark batch jobs running on Amazon EMR processed these Avro files in the same region into Hive-partitioned Parquet tables which were then presented into Redshift via Glue catalog. The Parquet tables were written as one-to-one or one-to-many projections of Kafka-topics, with Spark transformations handling normalization and decryption.
Kafka pipelines managed by the Afterpay data team process over 9 TB of data daily and deliver data to critical business domains such as Risk Decisioning, Business Intelligence and Financial Reporting via ~200 datasets. In the legacy design, duplicate events from Kafka’s “at least once” delivery required downstream cleansing by Data Lake consumers and late-arriving records added substantial re-processing overheads.
Evolution of Afterpay’s legacy Kafka pipelines to Teleport happened in three phases. Each phase was executed in response to business requirements and optimisation opportunities.
Phase I: Converging Afterpay Frameworks into Block’s Data Ecosystem
Afterpay aligned its Data Lake architecture with Block by adopting Databricks as the primary compute platform and Delta Lake on S3 as the storage layer. As part of this transition, all Parquet tables living in APSE2 S3 were migrated to us-west-2 (USW2) S3 as Delta tables, colocating data with downstream compute.
Databricks offers the following out-of-the-box features that address some of the challenges in Kafka processing, eliminating the need to reinvent the wheel:
Autoloader handles late-arriving records with fault tolerance and exactly-once processing through checkpoint management, offers scalability to discover a large number of files, and supports schema inference and evolution.
Delta Live Tables (DLT) provides:
apply_changesAPI that handle Kafka data deduplication efficiently by merging incremental records into target tables; and- In-memory and in-line Data Quality (DQ) checks.
Leveraging the above capabilities, we developed Kafka Orion Ingest (KOI) – a fully meta-programmed framework for processing Kafka archives. Pipelines in KOI comprise:
- A DLT job for transformations deployed in USW2;
- Dynamically rendered Airflow DAG for orchestration; and
- SLA alerting and in-line DQ checks.
All of these components are instantiated by simple metadata entries, simplifying deployments and maintenance.
As shown in the figure, KOI reads incremental Avro files via Autoloader, applies transformations and DQ checks, and writes external Delta tables to S3. These Delta tables are added to consumer catalogs and published to downstream services.
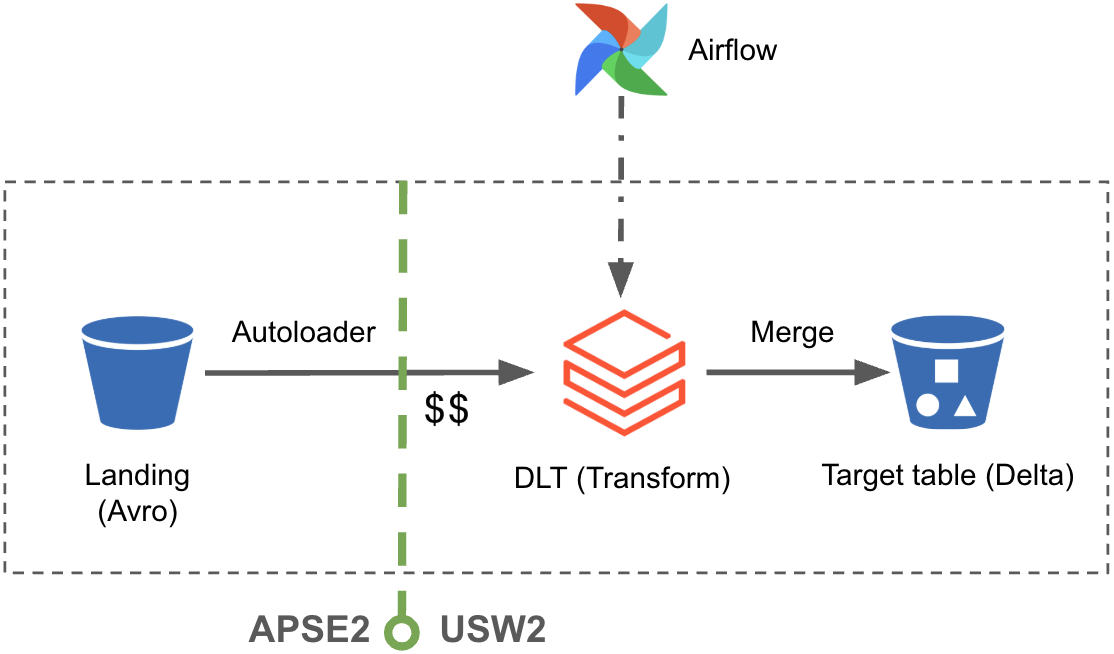
Alternate approaches considered for Kafka archival and ingestion
In an ideal, cost-effective architecture, source data, compute and the target tables would reside in the same cloud region. However, Afterpay’s practice of event archival in APSE2 S3 presented two key challenges in the convergence towards Block’s USW2 based Data Lake:
-
Migration of historical S3 objects and Kafka connectors from APSE2 to USW2 projected a huge one-time cost and engineering overhead.
-
Maintaining records for the same topics across two regions would add complexity to backfill operations1 and data reconciliation.
As a trade-off, Afterpay data team adopted a hybrid approach:
- Existing Kafka topics continued to land in the APSE2 region, preserving historical archival patterns.
- New topics were directly landed into USW2, inline with cost effective architectural practices.
Phase II: Egress Reduction by Data Compression
Empirical analysis of Afterpay Kafka data showed that Avro to Parquet conversion achieves compression ratios close to 50% on average. This observation suggests that Parquet format is a better candidate for cross-region egress.
As Phase II, we added new clusters in APSE2 so that transformed records are moved across regions as Parquet files. This change reduced APSE2 - USW2 egress cost by ~50%.
Merge cost problem
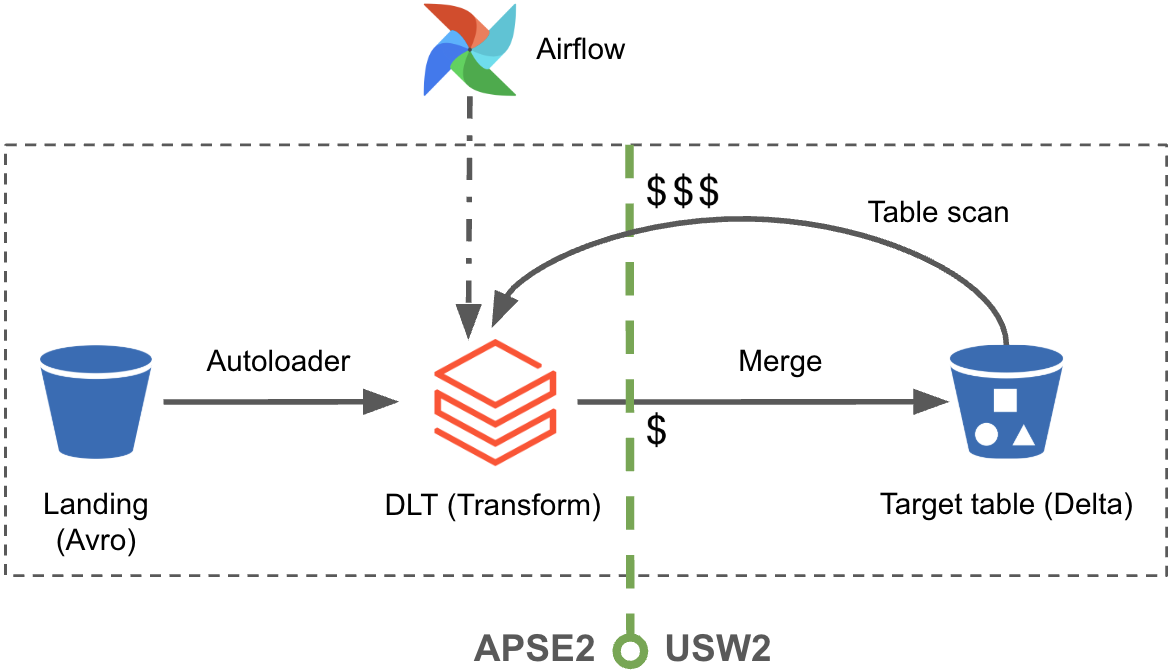
While APSE2 egress cost was substantially reduced by Phase II, we now had a new cost challenge resulting from cross-region merges!
Delta Lake merge operations compare key columns to update or insert only necessary rows and leverage deletion vectors to track changes without rewriting files. Incremental merges into the target tables thus require the key columns to be loaded into the compute memory. With the target tables in USW2, and the compute in APSE2, each merge operation triggered costly data transfers from USW2 to APSE2 – moving huge numbers of parquet data.
At its peak, these merges incurred over $1,500 per day in S3 egress — an unsustainable expense as our data volumes continued to grow.
Phase III: Optimal Cross-Region Merge Using Teleport
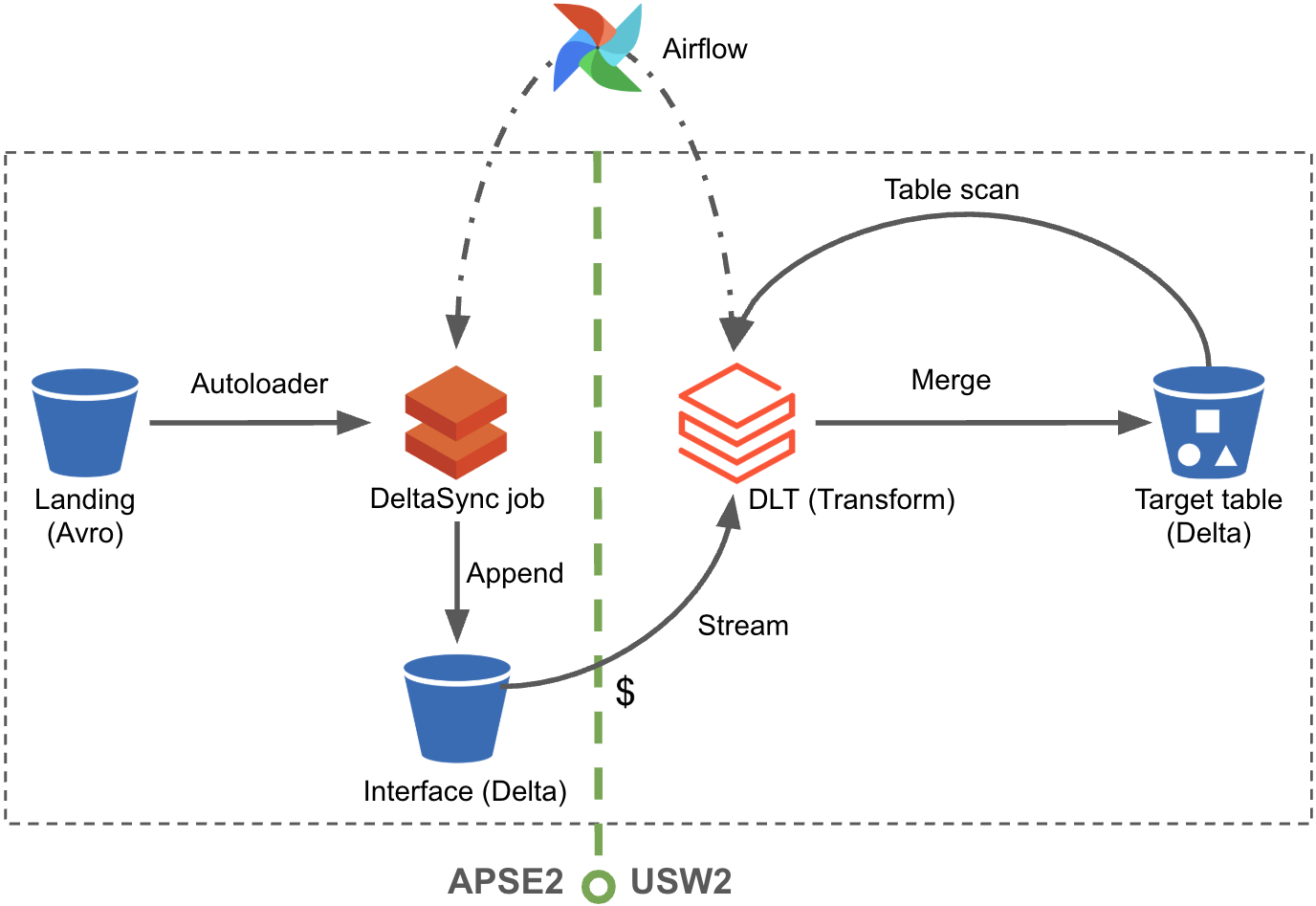
Teleport workflow consists of three major components split into two stages of execution. Between the two stages, a “streaming interface”, implemented as a Delta table in APSE2 S3, maintains the latest records from the Avro files within a moving window. The stages involved in Teleport are:
Stage 1. DeltaSync jobs read incremental Avro files for each topic and append them to the corresponding streaming interfaces.
Stage 2. DLT jobs deployed to USW2 use Spark streaming APIs to read new records from the streaming interfaces, apply transformations, and perform incremental merging into the target tables in USW2.
Teleport achieves optimal cross-region merge as a result of:
- Transferring compressed Parquet files (format used by Delta) from APSE2 to USW2 compute, retaining the advantages of Phase II;
- Performing merge operations entirely within USW2; and
- Ensuring minimal and predictable S3 storage costs by keeping the streaming interfaces transient.
These steps are orchestrated using Airflow that uses metadata configurations to determine whether to use a Phase II workflow or Teleport.
Design considerations
Catalogue-free streaming interface. By implementing the streaming interfaces as Delta tables on S3, we eliminate any need to rely on a catalogue for table maintenance operations such as creation, deletion, and vacuum.
Localised auto compaction. In Databricks environments, auto compaction jobs execute asynchronously after a Delta table is successfully written. As an additional optimization, interface tables are placed in APSE2 – allowing Databricks auto compaction to run locally.
Open source commitment. In line with Block’s commitment to open source, all the additional elements introduced by Teleport use the open source Delta format and native spark APIs. A highly available and scalable implementation of Airflow (also open source) is our standard orchestrator.
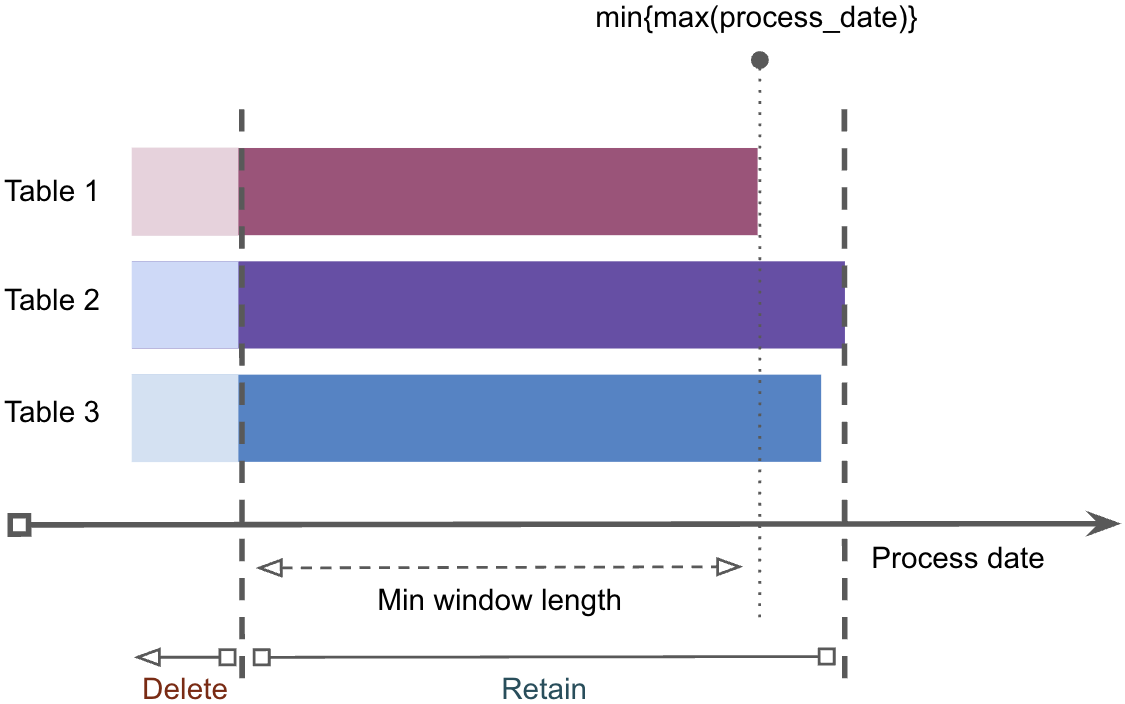
Sliding window implementation
The sliding window logic used to implement streaming interfaces (as Delta tables) ensures that only a fixed amount of recent records are retained while older ones are automatically deleted (and vacuumed) once all dependent target tables are refreshed.
Benefits of a sliding window approach:
- Prevents accidental data loss due to race conditions arising from the concurrent executions of DeltaSync and DLT jobs.
- Despite the use of a transient interface, late arriving records are guaranteed to be processed as long as they arrive within a defined window length.
- Facilitates reconciliation and data validation, keeping recent records available for ad hoc queries and DQ checks.
The following figure demonstrates how the window moves dynamically based on refresh frequencies across three target tables: Table1, Table2, and Table3.
A Strategy for Seamless Migration to Teleport
A Spark application periodically saves its state and metadata as streaming checkpoints to a specified prefix in fault-tolerant storage systems like HDFS or S3. These checkpoints enable a Spark application to recover and resume processing seamlessly after failures or interruptions.
Phase II DLT jobs use Autoloaders in directory listing mode to incrementally process landing Avro files, with each target table maintaining checkpoints to track successfully processed files. Migration of Phase II DLT jobs to Teleport without preserving the checkpoints would trigger a full re-listing of Avro objects in S3. This would cause significant delays and substantial compute costs.
To mitigate the above challenges, we devised a “hard cut over” migration strategy that transfers the existing checkpoints from Phase II DLT jobs to the DeltaSync job, ensuring zero impact to the downstream user experience.
Avoiding history reprocessing using a “Checkpoint Transfer” job
![]()
Transitioning of Phase II DLT jobs to the Teleport workflow was carried out by a separate “Checkpoint Transfer” job in three steps:
Step 1. Initialise the streaming interface by creating an empty Delta table, replicating the source Dataframe structure.
Step 2. Migrate Phase II DLT Autoloader checkpoints to the Teleport interface table checkpoint2 location. At this point, the interface Delta table remains empty, but the migrated checkpoints “trick” the DeltaSync job to think that all historical records have been processed.
After the checkpoints are migrated, the DeltaSync job is executed, loading only the newly landed Avro records into the streaming interface.
Step 3. Once the interface Delta table is populated, trigger the initial execution of Phase III DLT job in USW2. Before its initial run, the DLT job in USW2 does not have any checkpoints and treats the interface table as a new source. During this first run:
- Records from the streaming interfaces are read and merged into the target tables in USW2.
- Processed records are then checkpointed ensuring DLT jobs can resume incremental updates moving forward.
Using this technique, DeltaSync and DLT checkpoints were adjusted to enable uninterrupted incremental processing of target tables during migrations.
Reconciliation of records post migration
A reconciliation job compares Avro files in the landing S3 with the target Delta tables to ensure that no data was lost during the migration. This validation job runs after each migration and checks the last seven days of records for completeness.
Using the migration strategy discussed above, a total of ~120 topics were migrated in batches with negligible cost overhead and zero downtime.
The Outcome : USD 540,000/annum in Savings
Bulk migrations to Teleport commenced in November 2024, with a planned completion by March 2025. The reduction in transfer costs measured by mid-March amounts to an annual savings of ~USD 540,000.
Figure below shows the change in transfer cost averaged over a 14 day rolling window for preserving data privacy.
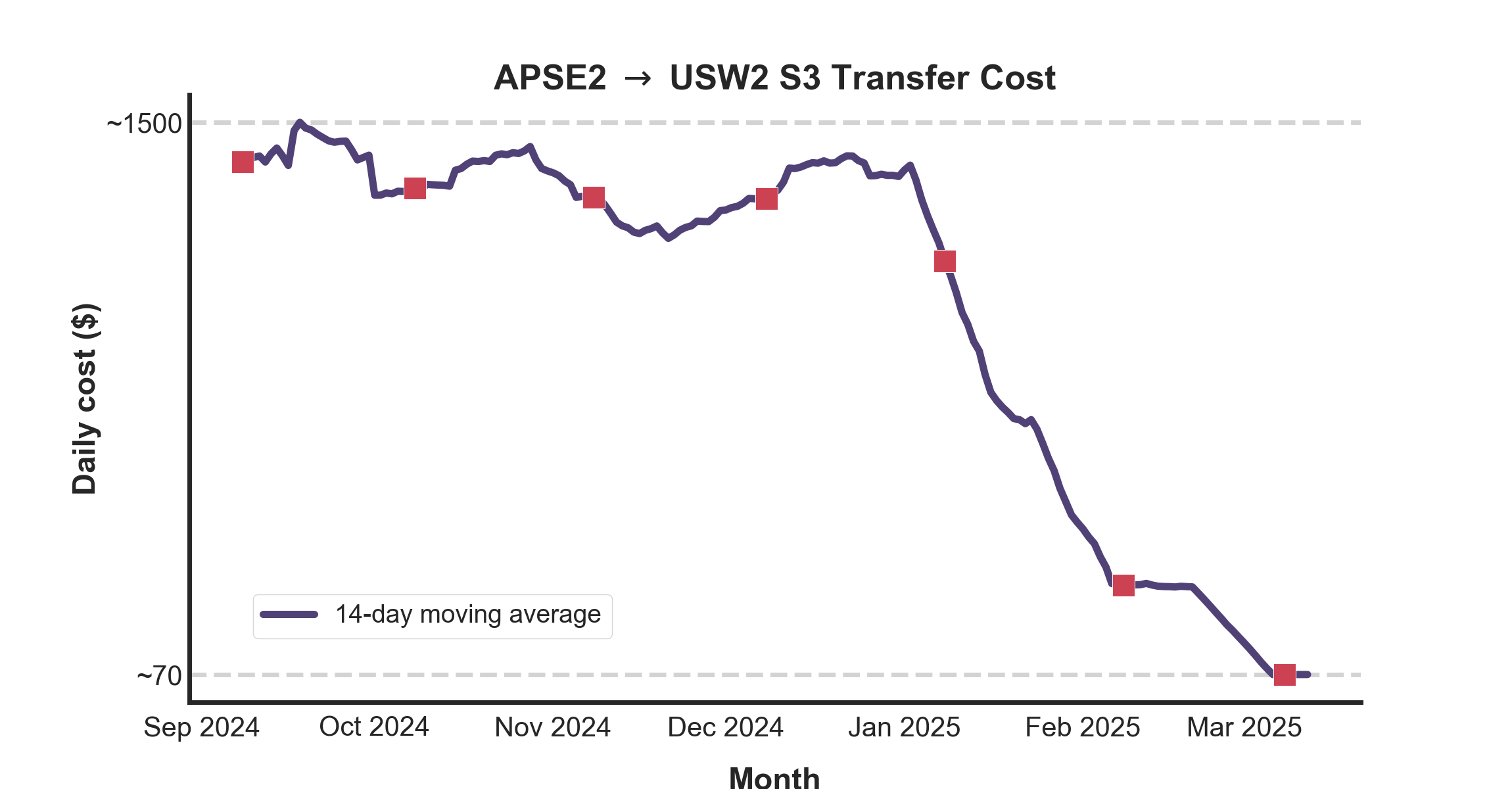
To further assess Teleport’s impact on reducing transfer costs, we analyzed S3 CloudTrail event logs, which track the total bytes transferred from USW2 to APSE2 for each S3 object. Once a table is migrated to Teleport, cross-region transfers from USW2 to APSE2 stop completely. Hence, the monthly savings for each migrated table corresponds to its pre-migration cross-region transfer cost. Our findings confirm that the cloud cost reductions can be directly attributed to Teleport migrations.
Project Teleport reinforces our commitment to agnostic engineering and open source, leveraging Airflow for orchestration and Spark APIs on cloud compute.
-
Databricks Autoloader performs periodic backfills by doing a full directory listing. Backfills may also be performed by engineers to refresh the records on a case-to-case basis. ↩
-
Note that, due to structural differences between DLT and Spark Streaming checkpoint directories, modifications to the checkpoint files are required for this transfer mechanism to work. ↩