Cash App on PlanetScale Metal
Intro
At Cash App, we have a few gigantic databases that we ask a lot of. Our solution to managing this kind of capacity has been to utilize Vitess, as a piece of middleware that sits in front of hundreds of otherwise normal MySQL instances, handling the hard work of figuring out what query traffic routes where.
We historically ran this in our own datacenters for many years, however alongside a larger cloud migration effort we elected to work with PlanetScale to move to their cloud managed product. This utilized their standard configuration of each VTTablet and MySQL instance cohabiting the same Kubernetes pod container, backed by a volume mount. VTTablet is Vitess’ middleware that fronts a single MySQL instance, which you can think of as the contact point for the SQL proxy. In this setup we can think of individual shards as essentially fairly normal MySQL servers.
Moving to PlanetScale was a game changer for the team, as we historically run pretty light, and time previously spent maintaining a fairly large bespoke architecture can now be spent on developer experience tooling that makes current and future developers’ lives easier. Over the course of the last few months Cash App and PlanetScale have been working together to migrate our fleet to their new product, PlanetScale Metal, and I wanted to dig in a bit into the whys and hows of this change.
Problems with Volume Storage
Over time after the migration we started noticing issues with our storage volumes. Periodically the volumes would slowly degrade, with performance draining over several minutes, before eventually recovering or dying completely. These events were happening often enough to generate some pager noise and thrash as we dug into the problem. Additionally, as we were in the final phases of cleaning up the cloud lift, we were unable to turn on PlanetScale’s Orc autofailover mechanism, meaning a person had to log in and failover the shard manually.
After consulting with our cloud provider, we decided to switch to a more advanced class of volume temporarily, which cost quite a bit more, but offered much higher availability guarantees. This did mitigate the waves of degradation, however, we ran into another issue: sometimes shards would fail to accept writes, at times for up to 15 minutes. During these periods write traffic would queue up in MySQL, making calls involving that shard much slower than usual. We unfortunately have a decent amount of cross-shard traffic, so this was problematic.
Talking with our cloud provider, it looked like what was happening was we were hitting our IOPS (input/output operations per second) limits with occasionally spiky traffic, leading to this unexpected failure mode. The advice was to increase our limit, however this was frustrating as this would be another bump in cost, and our traffic is generally fairly predictable in most cases.
What is Metal anyway?
Given all these challenges, PlanetScale proposed utilizing their new Metal product on our workload. Metal is unique in the way it utilizes our cloud provider’s instance compute, running on the fastest NVMe (nonvolatile memory express). Rather than utilize separate storage and compute, the machines instead have their own physical storage. This is intended for high throughput data loads such as MySQL, cutting down on hops to get to your data and providing a more consistent failure path when things go wrong.
This, of course, comes with the tradeoff of your machine and data being tied to each other. With traditional volume storage, if the machine goes down, you simply mount it to a different one and are back in business. With instance storage this scenario requires rebuilding the replica. This is a big part of why enabling semi-sync replication is a prerequisite for using Metal, as you have confidence that writes won’t drop on the floor. Additionally, PlanetScale’s backup restore system is very well exercised; it’s a normal part of verifying the backup process every time it’s run.
managing costs
The other big difference is Metal bundles up the components you need to run a database shard into a single machine, potentially providing savings compared to a traditional standalone compute + volume storage setup. The two components in that setup are billed separately, with the quota of IOPS required for storage coming at a premium for our needs. When we move to instances the compute and storage come at a single cost, and with Metal, there is virtually no limit on the max amount of IOPS. Thus by using the local storage built into Metal we remove the unbounded risk of costs associated with buying more IOPS from cloud providers.
p99 off a cliff
The cost savings are nice to be sure, however day-to-day the real wins come from the stability and power of running on this kind of setup. Since moving, we’ve seen much more predictable failure modes, where write buffering is a thing of the past. Additionally, the changes to p99 latency were dramatic, cutting our main workload by 50%.
Additionally, during a recent event we saw query traffic double beyond normal values for a period, and while this was happening response times and metrics were very comfortably nominal, something we certainly haven’t been able to say in the past.
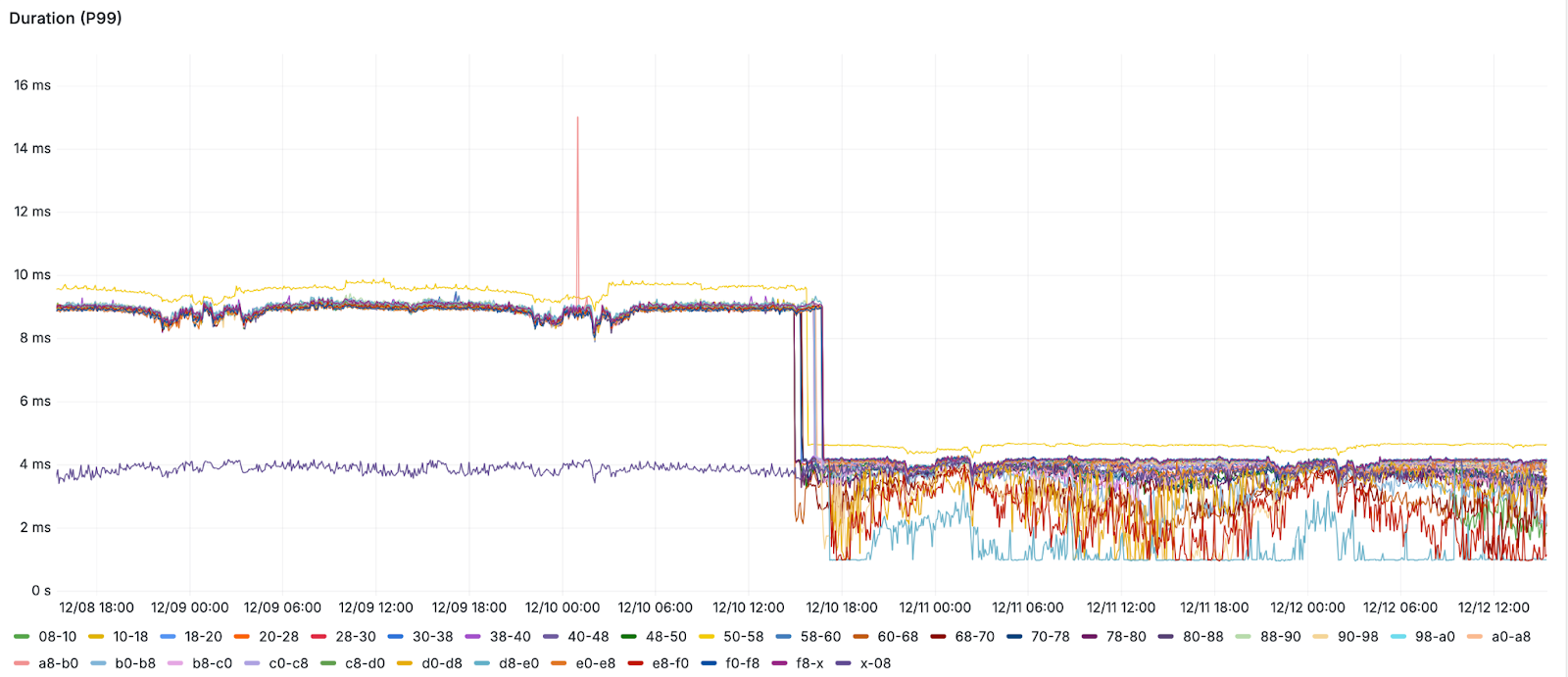
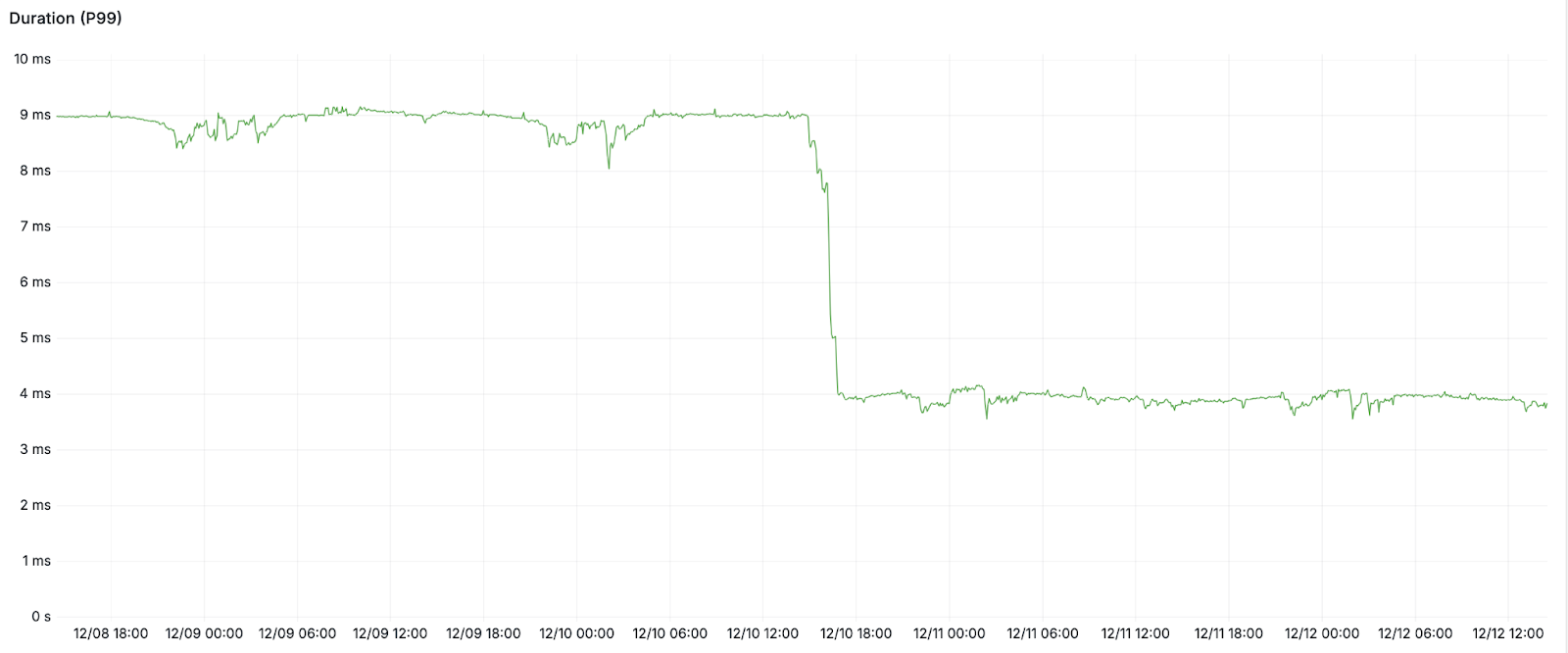
We are very happy with our decision to migrate to PlanetScale Metal which enabled us to achieve the rare outcome of improvements in performance, cost, and reliability – a win for our customers and our business.