Encryption using data-specific keys
At Cash App, securing our customers’ data is not just a priority - it’s a responsibility. One cornerstone of our approach to achieve that is encryption. We’re obsessed with it. We’ve been using encryption at the application layer so much that our security team’s motto is “encrypt everything”. Application layer encryption specifically has been our bread and butter because it removes the data storage tier from the compliance scope and security threat model, allows granular access control over who can decrypt the data, enables easy integration with privacy regulations, and much more.
Introduction
In the last blog post we wrote about Application Layer Encryption in AWS
back in **checks notes**… 2020, we discussed how we’re creating KMS instances and Tink
keysets for Cash App services running in the cloud.
Here’s a quick reminder of the general layout of how it works:

- Each service in our cloud backend has its own KMS Customer Managed Key (CMK) instance associated with it.
- To create a new service encryption key, we’ll generate a Tink keyset and then call the necessary CMK to encrypt it (using envelope encryption).
- The encrypted Tink keyset is then persisted in the service’s resource folder; and committed to Git.
- When the service starts up, it calls the CMK to decrypt the Tink keyset, and then store it in-memory to encrypt/decrypt data as needed.
Things have changed quite a bit in our app-layer encryption setup from that original design. Our initial approach was tailored to secure the data managed and stored by individual services. In that design, encryption keys were tightly coupled with the services using them, aligning well with our early needs. However, as we expanded app-layer encryption to encompass our data transport infrastructure—spanning gRPC and our Kafka event bus—this service-centric model began to show its limitations. The tight coupling made the system less flexible and more challenging to scale. To address these challenges, we evolved our encryption strategy. The next generation of app-layer encryption shifted from a service-centric model to a data-centric model, decoupling encryption keys from individual services and instead associating them directly with the data itself. This change enabled us to maintain robust security while enhancing flexibility and scalability across our infrastructure. We refer to this latest evolution of our encryption infrastructure as “Data Keys”.
There are 2 main differences between these approaches. First of all and most importantly, we switched from having a map of (CMK instance → service) to a (CMK instance → encryption key). That might seem like a minor detail, but it is very significant; it means that encryption keys can be associated with their own independent CMK. This makes it possible to have multiple services access the same key.
Secondly, moving away from service-centric keys also affects where encrypted key material may be stored, such as in a more accessible S3 bucket instead of in the service’s resources directory.
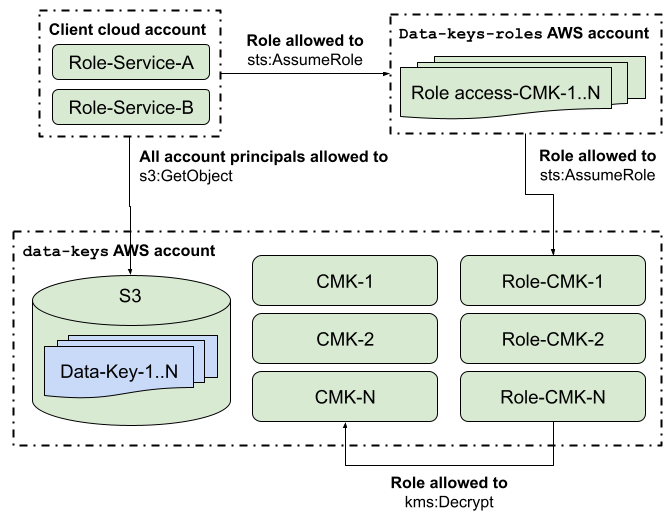
Key Access Controls With IAM
When an encryption key has its own CMK, an AWS IAM policy can be attached to the CMK defining which roles can access it, and what APIs they can use.
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:sts::<data-keys-roles-account-id>:assumed-role/key-name/session-name"
},
"Action": [
"kms:Decrypt"
],
"Resource": "*"
}
}
When specifying the AWS Principals in the IAM policy, assumed-role session principals can be used to ensure that only roles assumed via AWS STS are allowed access. When clients rely on short-lived, dynamically generated access via STS, it reduces the risk of long-term credential exposure and limits the impact of compromised access.
A relevant IAM Role can be defined for each encryption key in a dedicated AWS account.
The AWS account data-keys-roles has a role for each data key (AKA “bastion role” or “access role”)
that grants permission to decrypt that data key.
This access role’s trust policy allows a role in other consumer accounts to assume the access role.
identified by the isolation of the role(s) in question. Thus, enabling access to our encryption keys
The “bastion role” pattern is one implementation of AWS’ “IAM Role Chaining” concept,
from different AWS accounts and business units in Block.

Key Storage In S3
Since encryption keys are no longer tied to a single service, it becomes impractical to store encrypted Tink keysets in the service’s resources directory or commit them to Git. To address this, encrypted Tink keysets can be stored in a dedicated S3 bucket within the same AWS account as the CMKs. This approach not only centralizes key management but also leverages S3’s built-in versioning, enabling the recovery of keysets in case of accidental deletion or overwrites. Security remains intact because the Tink keysets are encrypted, and access to the corresponding CMKs is strictly governed by IAM roles, ensuring that only authorized services can decrypt them.
Provisioning Data Keys
So far, we’ve described the following resources needed in this design:
- CMK per encrypted Tink keyset in the data-keys account
- IAM Role for each KMS instance in the data-keys account
- Encrypted Tink keyset stored in an S3 bucket in the data-keys account
- IAM policy for each CMK specifying the role above as the principal in the data-keys account
- IAM Role for role chaining in the data-keys-roles account
- IAM policy specifying which principals can assume the role in the data-keys-roles account
Provisioning these AWS resources should be easily accomplished using Terraform. Creating and encrypting the Tink keysets is straightforward with tools like Tinkey. And the last remaining step is to upload the encrypted keyset to the dedicated S3 bucket.
All of the above tasks are easily accomplished in a simple bash script, and executed via most CI platforms. Which means that now, key provisioning and management is completely self-served, fully audited, and automated.
Lessons Learned
The main improvement with this design is the de-coupling of encryption keys and services. The ability to share encryption keys between services and workloads, and even other cloud accounts and consumers naturally led to the situation that keys became associated with the data they protect.
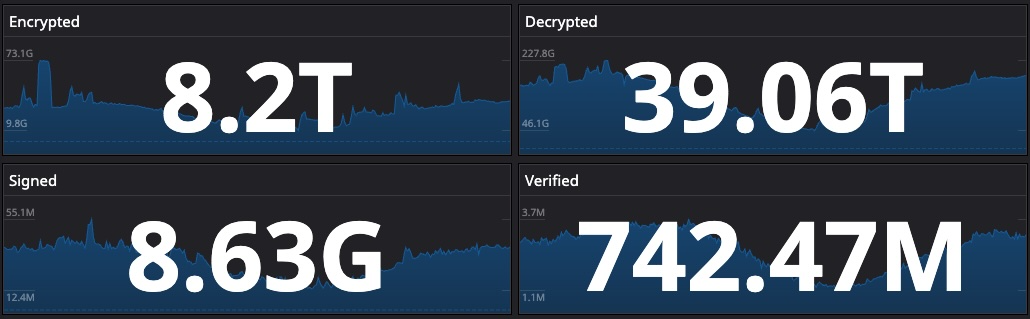
For example, encryption keys can be created per Kafka topic. Any workload or service that needs to produce or consume data from a specific topic, must have access to that topic’s encryption key. In fact, this change in how keys are being provisioned and used was so much easier and friendlier for engineers to use, that it led to a big spike in adoption of data encryption and keys being created that we’re now encrypting on average more than 8TB of data a day.
The same happened with protocol-buffer messages (to be continued)…