Cross-Shard Queries & Lookup Tables
This post is part of Square’s Vitess series. Check out previous posts here, here, and here.

Sharding Cash’s database with Vitess was a massive undertaking that set us up for the future, but it was just the start of the journey. The sheer rate of growth of our traffic necessitated a focus on splitting the data to multiple machines as quickly as possible. Migrating from a traditional database to a distributed one requires some careful consideration, as subtle effects become evident when your data access patterns change. Failing to account for some of these effects will actually degrade performance as you add more hardware under the hood.
The Entity Group Model
Cash organizes data in Vitess around the concept of Entity Groups. An Entity Group is simply a row of data in one table (the Entity Group Root) and all the rows associated with that row (the Entity Group Children). All the Entity Group Children store the ID of the Entity Group Root, and so you are able to shard your data off of that ID, thus guaranteeing that everything tied to that Entity Group will live on the same shard.
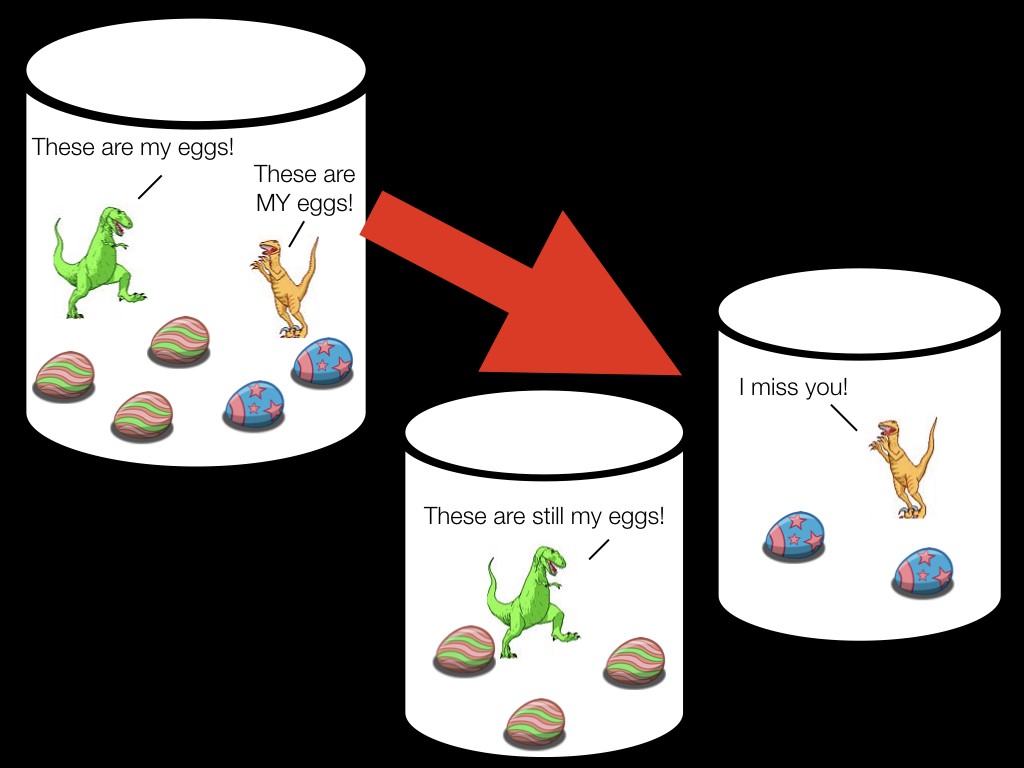 Entity Groups in action.
Entity Groups in action.
Vitess sits between your application and several MySQL instances, presenting what appears to be a normal MySQL interface to the application layer. As query traffic passes through it might examine the WHERE clauses looking for hints as to which shard your data is actually on. Thus if you’ve sharded your database of dinosaurs by ID and you were to do something like:
SELECT * FROM dinosaurs WHERE dino_id = 32
Vitess can look at that dino_id = 32 and determine that it lives on shard B, which, according to Vitess’ internal topology map, lives on MySQL database 002. Vitess will thus transparently route your query to that database and you can carry on with your work.
Suppose you have another table of eggs, where each egg is owned by a specific dinosaur. In the Entity Group model the dinosaurs are thus Entity Group Roots and the eggs are Entity Group Children. Each egg row would thus have a dino_id representing it’s owning dinosaur.
Legacy Code Has Scatter Queries, and That’s a Problem
The beauty of Vitess is that it makes a massively distributed database look like a plain old MySQL instance to your application layer, but the reality is that you’re still talking to a massively distributed database. If you’re starting with sharding in mind from day one (as Misk does) it’s quite simple to deal with these issues; however, when you’re shifting from a traditional database topology on the fly, some of your assumptions will have to change.
In a single database system you might search for a specific egg by ID:
SELECT * FROM eggs WHERE egg_id = 24
This would work fine: you fetch the egg row and carry on with your business. However the dinosaur database scene is exploding in popularity and you now have way too many eggs to reliably serve from one database. You set up Vitess, make a bunch of shards, and continue shipping features. The problem, however, is WHERE egg_id = 24 gives no clue whatsoever about what shard you’re trying to access. Vitess therefore has no choice but to search all your shards. Under the hood the middleware will fan out your query to all the dinosaur shards it knows about, then collect the output into one result set: a classic scatter-gather pattern.
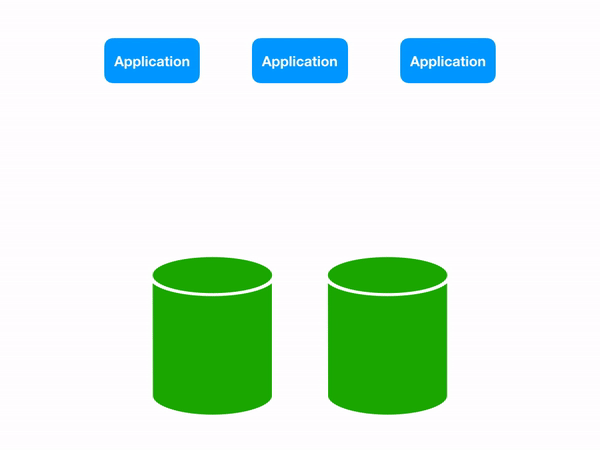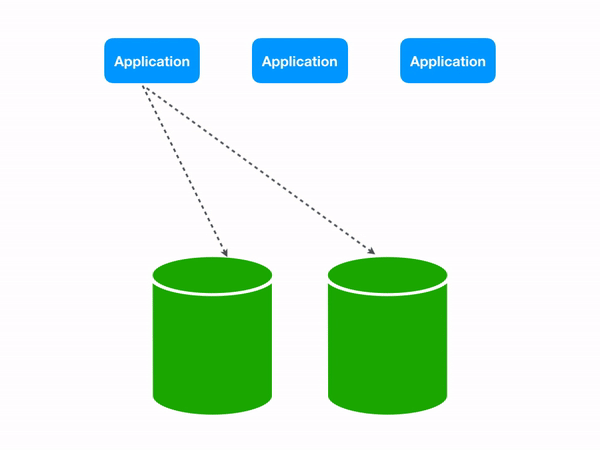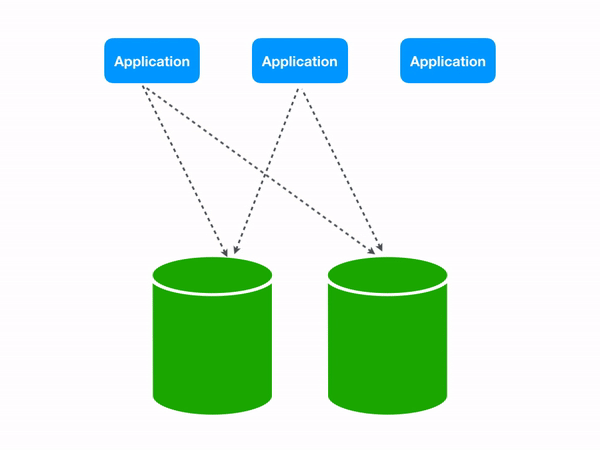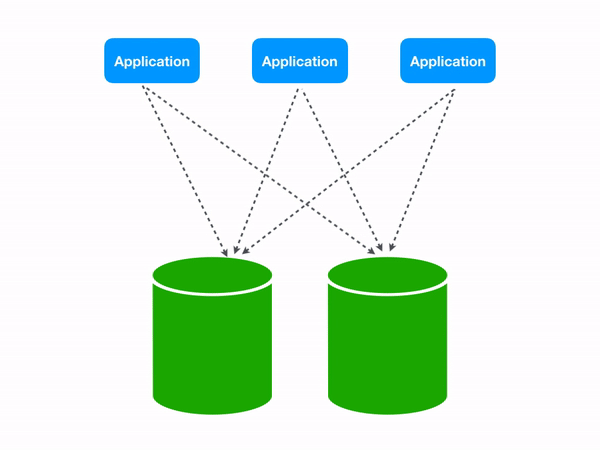 Three scattering queries each perform an extra database round trip in a two shard topology.
Three scattering queries each perform an extra database round trip in a two shard topology.
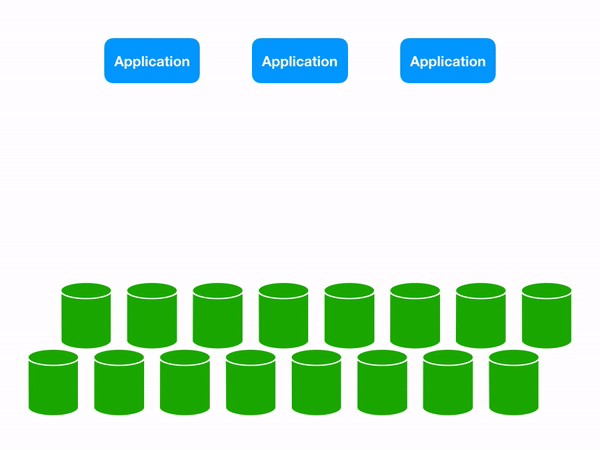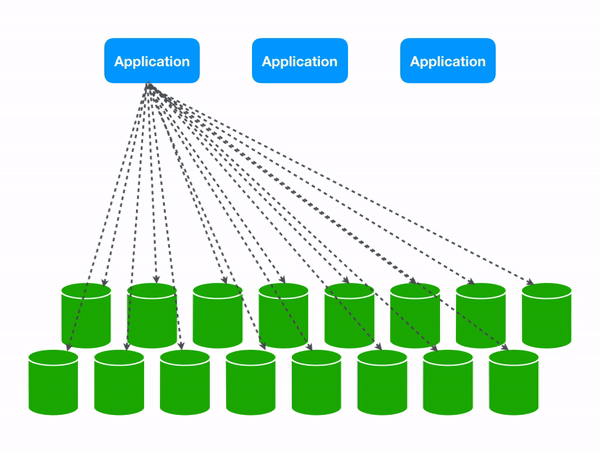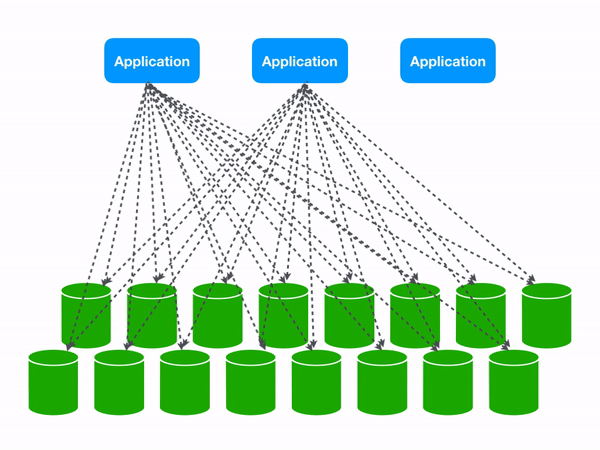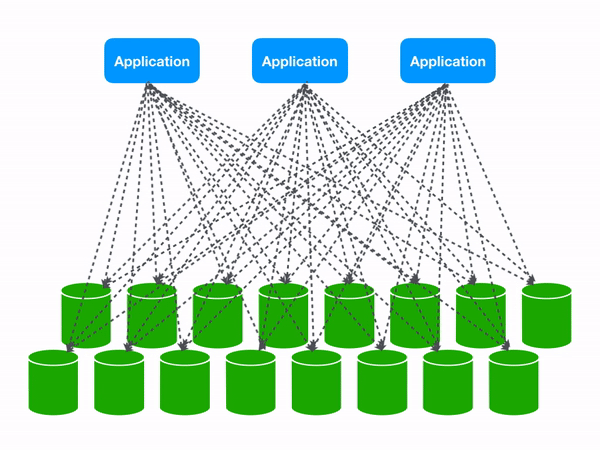 Those same three queries become a lot more expensive at 16 shards.
Those same three queries become a lot more expensive at 16 shards.
This, of course, is something we knew about before undertaking the work of sharding the database. However, only queries which do not contain an Entity Group Root ID will do this. Such queries were in the minority, so splitting the load to two or four or even eight shards is still an improvement. After performing a split which doubles your shards, if each of your shards is taking 70% of the traffic the previous shards were taking, that’s still a win. But as the shard count rises, those scatter queries become more and more expensive. One way to think about it is that as your data shards, your scatter queries don’t — if one database instance was receiving 10,000 queries per second from scatters before sharding, both new shards will each be receiving 10,000 queries per second from those scatters. Your databases spending time processing all these fanned-out queries means that they have less headroom for processing other queries.
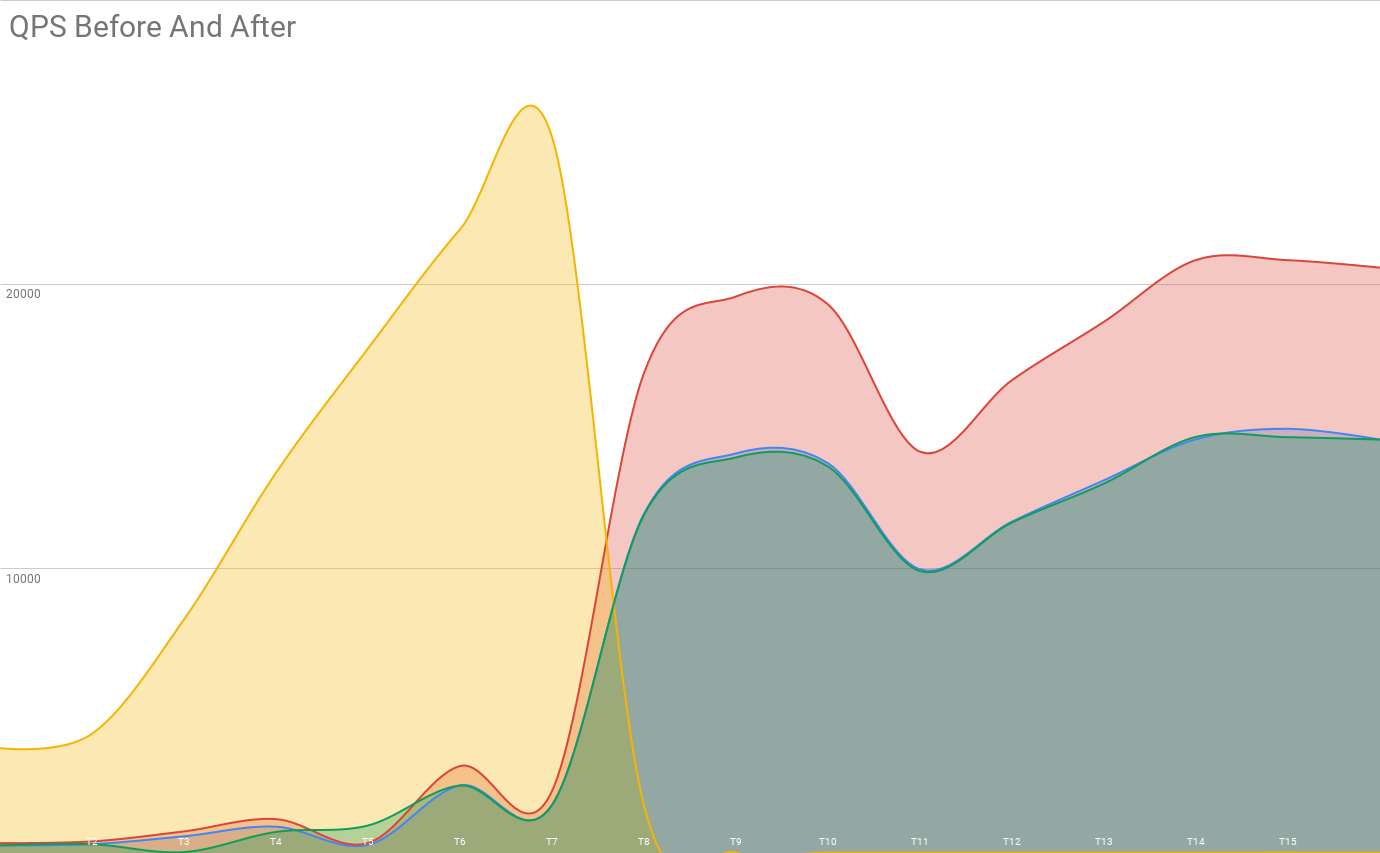 These are some actual query metrics from a split from 1 to 3 shards, with one shard containing one half of the data of the original one. The two smaller shards’ QPS are almost identical, however they aren’t even close to the 1/4 you would expect!
These are some actual query metrics from a split from 1 to 3 shards, with one shard containing one half of the data of the original one. The two smaller shards’ QPS are almost identical, however they aren’t even close to the 1/4 you would expect!
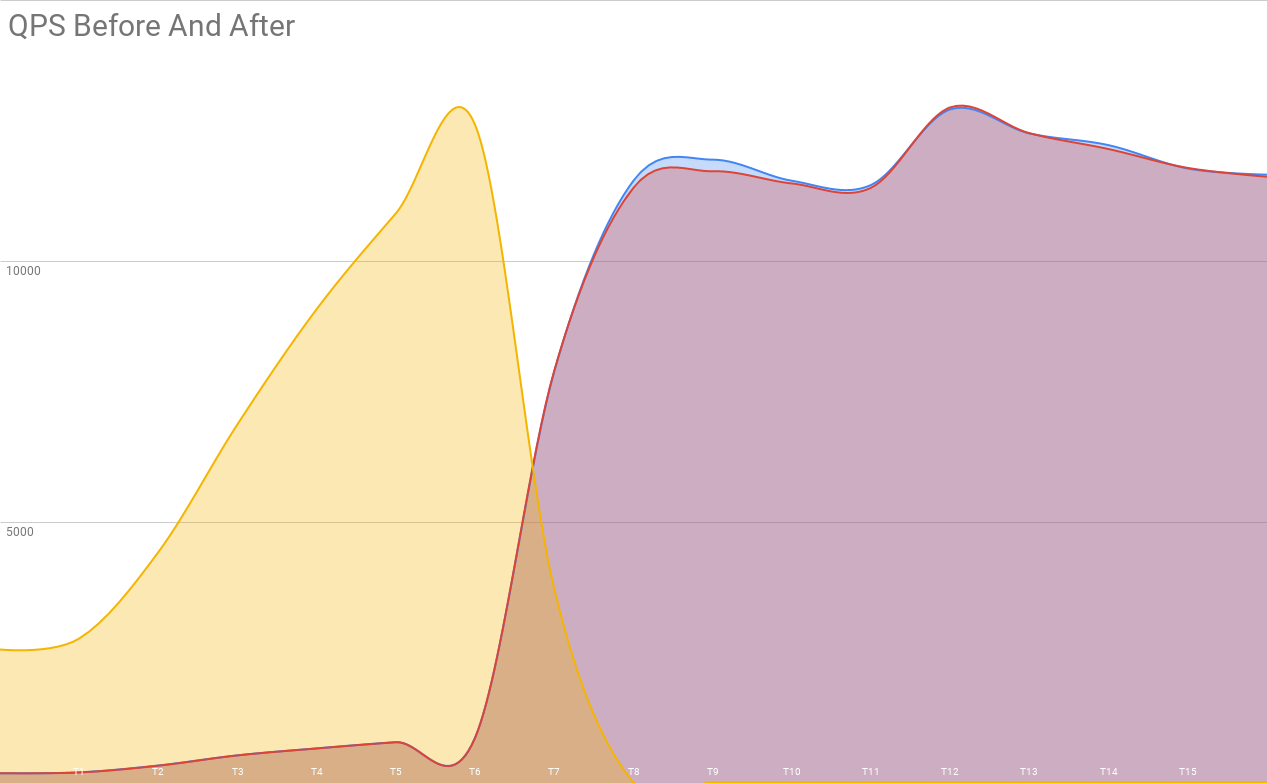 This is a later 50/50 split, which is even more unsatisfying! At this point we had enough shards that it was definitely Time To Do Something About This.
This is a later 50/50 split, which is even more unsatisfying! At this point we had enough shards that it was definitely Time To Do Something About This.
So how do you fix this problem?
Taking a Pulse
The first step is to identify queries that are doing this. If you’re worried about sharding your huge database, chances are your codebase is already quite large and complicated; manually scrubbing scatter queries from the codebase will be a nonstarter.
Fortunately, Vitess provides stats on decisions it’s made while filtering SQL through it’s query planner. Queries that have a distinct signature are cached and counted¹, and are available on a very convenient debug page. Thus it’s simple to check that SELECT * FROM eggs WHERE egg_id = :val has been called 45,000 times and results in a SelectScatter, which is Vitess-speak for “I had to look everywhere for this data”.
We wrote some fairly simple tooling to analyze Vitess’ query plan stats page to identify the worst offenders. The results were pretty sobering: 25% of our database traffic was a result of scatter queries. Ouch!
This is a dumb use of a lot of hardware. How did we make it better?
Making The Code Vitess-Aware
One technique was to simply fix queries to provide the sharding key. For instance, this query can be correctly targeted to a single shard:
SELECT * FROM eggs WHERE dino_id=32 AND egg_id=24
Obviously this requires knowing the ID of the dinosaur beforehand, but in practice, rows like this are often lazily loaded by our ORM (Hibernate), so the ID is floating around unused in the code. With a little work, it can be quite straightforward to simply add the extra parameter to a generated query.
Vitess’ query planner is clever but does currently have a few blind spots. There are long-term plans to patch these holes, but in the meantime we made some modifications to the application. One might expect something like this to shard target appropriately:
SELECT * FROM eggs WHERE (dino_id, egg_id) IN ((32, 24), (34, 12))
However it will actually scatter!
Fixing it requires an additional incantation that exists only to give Vitess a hint of where to look:
SELECT * FROM eggs WHERE dino_id IN (32, 34) AND (dino_id, egg_id) IN ((32, 24), (34, 12))
Fortunately most of our queries are created in query-generator classes, so adding this additional information in a central location was relatively straightforward.
Using a Table of Contents
There is another class of problems that can’t be fixed by the application. Suppose all you have is a list of egg IDs and you want to find their owner dinosaurs. Clearly if you’re trying to find dinosaurs you don’t know their IDs! Fortunately Vitess has a feature to solve this problem: Lookup VIndexes².
A VIndex is Vitess’ concept of a distributed index. Much as a database index uses information within the query to find the row you’re looking for efficiently, a VIndex uses that same information to find the correct shard. A Lookup VIndex is a special VIndex that’s backed by a database table and intended to solve this very problem. The way it works is quite simple: the eggs table would be configured at the Vitess level to have a Lookup VIndex, let’s call it eggs_egg_id_lookup. This would correspond to a table that has an egg_id and dino_id column. Now whenever the eggs table is changed, the lookup table will be updated to have the appropriate pair of fields. Now, when you perform your query, Vitess knows that there’s a VIndex on the eggs tables’ egg_id column and will consult it to find the dino_id associated with it.
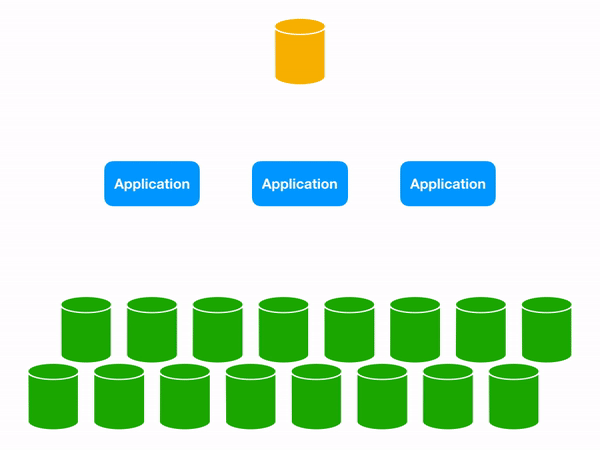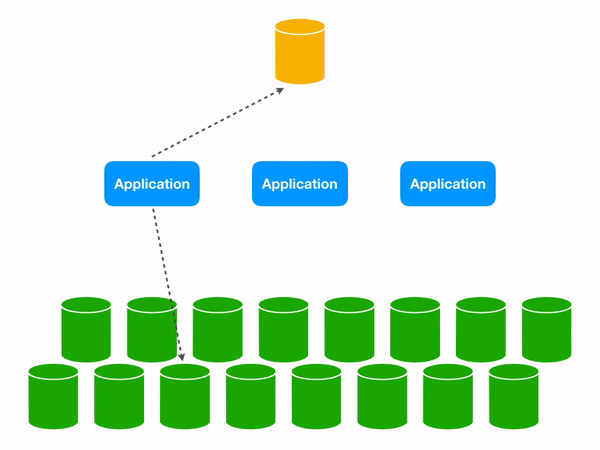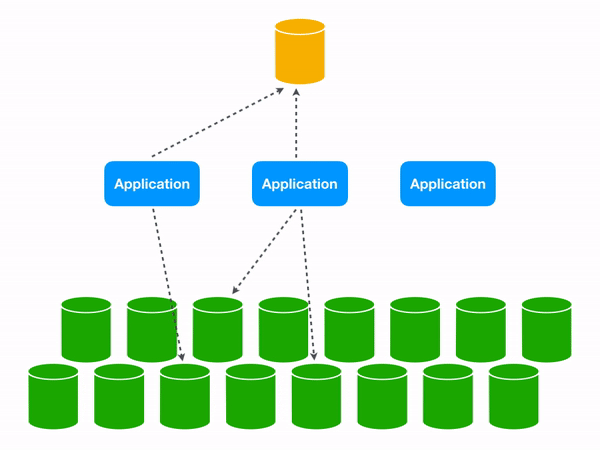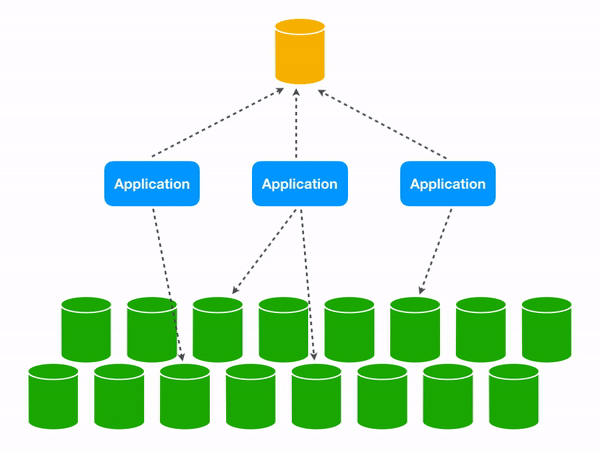 Using a Lookup VIndex lets us target the appropriate database shard.
Using a Lookup VIndex lets us target the appropriate database shard.
There are a few considerations to take into account when using this technique. Consulting a Lookup is an extra round trip to the database, which will add a bit of latency to the overall query. However, this is definitely preferable to hitting every single shard! A side effect of this method is that the Lookup needs to be updated before the data. The lookup entry and data have different sharding keys so they need to be updated in separate transactions³. If the lookup were to be updated in the second transaction and failed, there would be no row acting as a map from that field to the shard ID. If you were to then query by the field Vitess would examine the Lookup, find nothing, and return no results. Not good. What instead happens is the Lookup is updated before any changes are made to the data, and if the second transaction fails we’re left with rows in the Lookup that don’t point at anything. This isn’t actually a huge problem, because a Lookup only hints that there’s something on a shard, not that it’s actually there. Until the Lookup is cleaned up (typically with a rebuild⁴) we’ll waste a query looking for data that isn’t there, but this is far preferable to being flat-out wrong.
There were some interesting bumps in the road to using Lookups as extensively as we do today. For instance building a new one requires backfilling the lookup table from existing data. Eventually we want Lookup VIndex maintenance to be pretty much the same as database index maintenance from an app developer viewpoint: invisible.
Another interesting problem was VIndexes didn’t support NULL fields. This has a lot to do with the fact that NULL is a special value in MySQL; NULL is never equal to anything, so a lot of the comparison logic in a Lookup goes out the window. In practice, though, when you’re working in an unsharded database, it is quite common to have NULL fields. Searches on those fields then become equally common. To handle existing queries like this, we added support for such fields in Lookup VIndexes. The change there was to map a NULL field to no shard at all, and making Vitess be OK with that. This comes with a side effect that a search for rows where a field is NULL probably won’t give you something useful without any other hints to go by, but I personally feel like that’s more of a feature: the alternative is to always scatter such queries, since you can pretty much guarantee every shard will have at least one such row.
Using Our Resources Wisely
Moving from a one-database world to a sharded one within an existing application was a Big Deal, but to get the most out of that we needed to be sure we were using our resources to their maximum potential. By methodically attacking our scatter queries using these techniques we’ve started to reap the benefits of all the little pieces of our data set actually behaving like the independent little pieces we need them to be.
This post is part of Square’s Vitess series.
¹ This in itself is why the CPU costs of performing query planning before passing the query off to the database for another round of query planning aren’t devastating.
² Vitess uses a naming pattern of adding a “V” before common database components. Just roll with it.
³ Two pieces of data with different sharding keys will most likely be on separate physical database servers, and thus there’s no way to ensure writes to both completed successfully without incurring the cost of two phase commits.
⁴ When we roll out a new Lookup it needs to be backfilled from the source table, and the simplest way to scrub junk rows from a Lookup is to start fresh. This used to be a job run by the application but we’ve recently added a feature to Vitess to have it backfill it’s own Lookups. The problem now is it’s too easy to make a Lookup. It is often better to write something a little more elegant that does the job without the extra overhead. Not the worst problem to have.