Brief History of Logquacious
Logquacious (lq) is an open source, fast, and simple log viewer written at Cash App. It supports reading structured log entries directly from an Elasticsearch log store. It is available on GitHub.
Here is a brief history, current state, and the future plans of Logquacious.
Reasoning
Logging is critical at Cash App for quickly working out issues over a mesh of microservices, where a single API request may traverse multiple services before being able to provide a response. Before Logquacious came along, Cash App used Kibana, the official open source Web UI for Elasticsearch.
Kibana has been around since around 2014 and while it is powerful, it also has an extremely complicated UI, and a large footprint. One example is that the static assets are large. Our current deployment of Kibana serves 4.5MB (compressed) scripts and media on an initial load, with a total of 45 requests overall. Compare that with the current release of Logquacious, which is 470KB with 10 requests. Over higher latency and low bandwidth connections it can be a struggle to use Kibana.
Another pain point is the use of the available user interface space. Ideally, users want a clean and simple view of the logs, which we think we have accomplished. The screenshot below of Logquacious shows a visually obvious place to search, with functionality available in the nav bar.
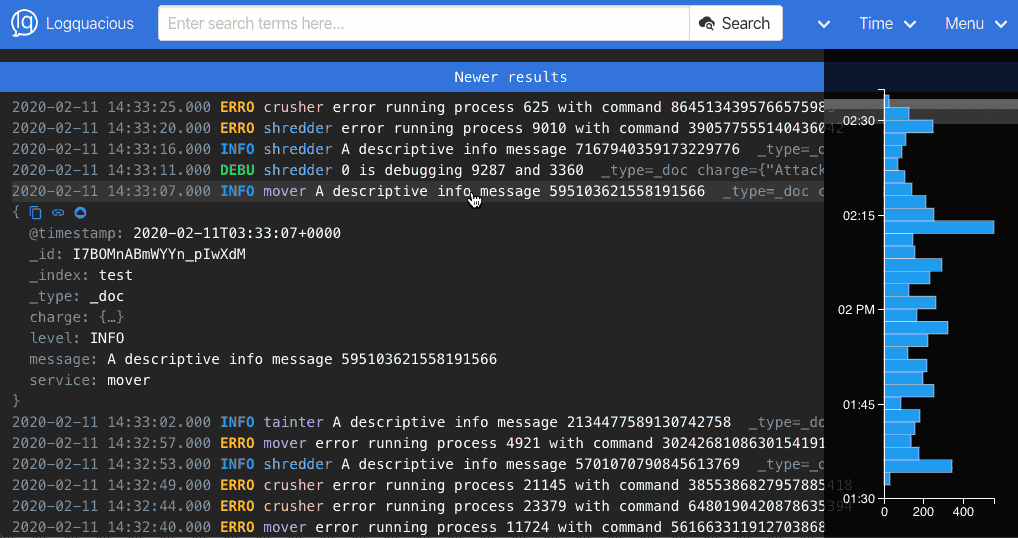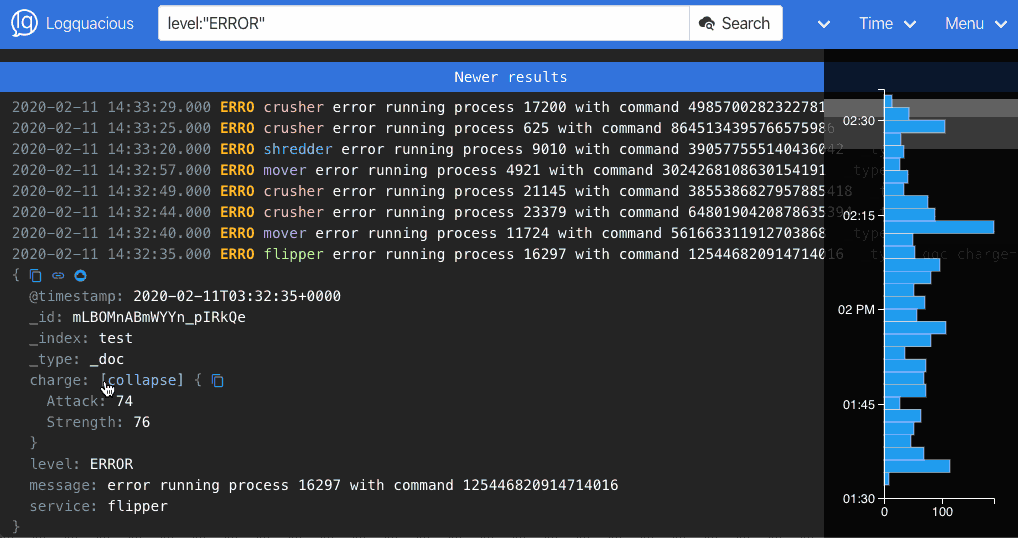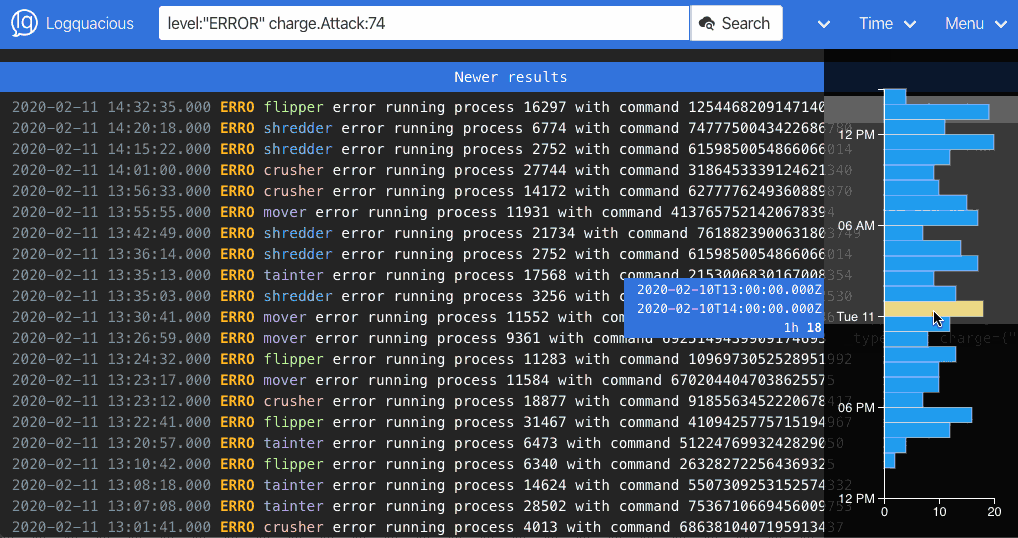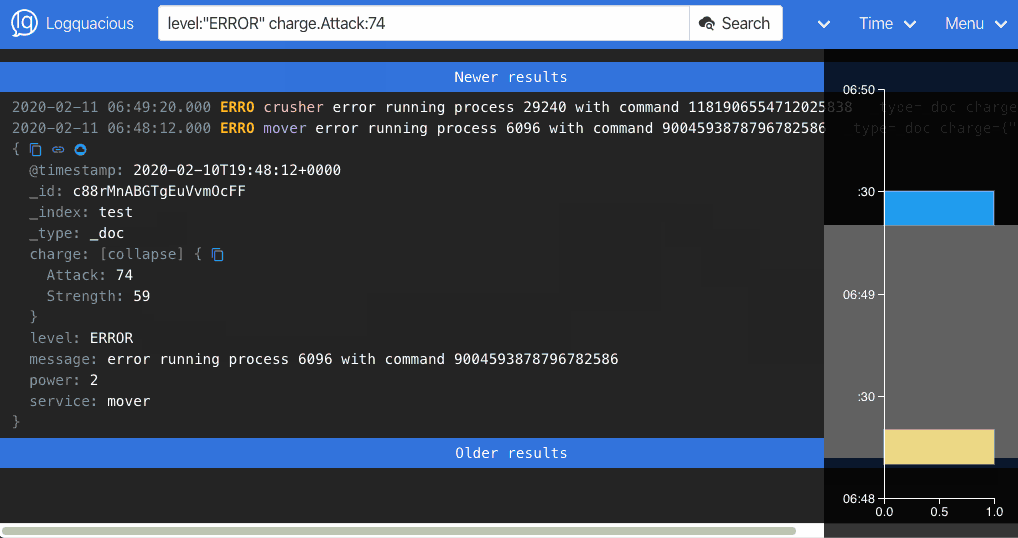
We feel Logquacious is a better choice than Kibana for logging because:
- It is lightweight and fast to load–less JavaScript and other media to download and parse.
- It is simple to use–just start typing a query.
- It is simple to install–use Docker or serve static files with a single JSON config file.
- It has low latency when displaying log entries.
- It shows more log entries on your screen–Kibana is overloaded with UI elements.
- It has certain logging specific features that Logquacious does better than Kibana, e.g. “view in context”, custom field transforms, etc.
Implementation Details
Initially Logquacious was written in React. Unfortunately, React was severely slow for scrolling and rendering many DOM entries. No matter what we tried we couldn’t make it performant enough. A decision was made to rewrite the code to use direct JavaScript DOM (“VanillaJS”) calls instead of using a framework to handle DOM generation for us. The rewrite was significantly faster.
The Elasticsearch interface has gone through a few major refactors due to some slowness with certain queries. Right now there are three API calls to Elasticsearch involved in displaying a single set of results.
The first request is fetching the minimal amount of data to display a single line to the user. It only includes the id, timestamp, and some core fields such as level, message, thread, and container. Afterwards, a second request is made based on the document IDs returned for the full set of data. This cuts down the time to display log entries, where the bulk of the data is loaded asynchronously while the user can see some of the logs they’re interested in.
The third request is executed at the same time as the first request. It is to collect the bucket count over the time range to populate the histogram. We can potentially merge this with the initial request since the Elasticsearch API has functionality to lump the two calls together, but will have to investigate if it increases or decreases performance.
From a maintenance point of view, VanillaJS was not ideal as there was a lot of cruft involved with UI components. We revisited the idea of using a web framework such as React again for the UI components, so that contributors would have a better time with the code base. While looking for alternatives, we found that Inferno is almost fully compatible with React, yet smaller and faster. It was a no-brainer to choose it. Everything except the optimised logging views were replaced with Inferno components. This reduced the size of the code base quite a bit and at the same time made it easier to work out the flow of the code.
As for custom configuration, there were many hardcoded features that had to be moved out into a new JSON configuration file. In some cases we had to completely remove some features as it was too specific for how we used it at Cash App.
Current State
- Fast and easy to use. It is the go-to logging search interface we use to find and share log entries across environments.
- There are many features planned, which are gradually being worked on.
- Not yet battle tested against other major Elasticsearch databases (as far as we’re aware).
- Occasional bugs pop up (which we quickly fix).
Needs Work
Just a few notes on what needs fixing in the short term. This is open to anyone to help out if they want!
- Documentation needs more work for some aspects. For example there are features that have been introduced recently but the documentation hasn’t been updated. The README.md is getting quite large and might need to be split up. The documentation needs more GIFs too.
- Still a few niggling bugs and UI glitches.
Future Plans
Live Mode
Live mode was awesome in our initial prototype. There is something so satisfying about seeing logs scroll by in real time in a web UI. We want it back, but there are problems.
Elasticsearch does not index documents immediately for performance reasons. Depending on your set up, this could cause entries to be several seconds or more behind reality, and have entries out of order.
We use fluentd internally to collect logs from Kubernetes. This has a similar problem with log delays and ordering.
One solution we’re considering is to allow log entries to simply be shown out of order and as soon as they’re available. The advantage is that if you’re only looking at a single Kubernetes pod for example, you will most likely see the logs appear in order anyway. A user could just hit refresh when they need the logs in order.
An alternative solution could be to delay everything to a certain amount of time. It reduces the usefulness of live mode, especially if you’re seeing 30 seconds or more of latency.
The other solution is reshuffling the logs as they come in to be in the correct order. The UI could highlight new entries when they’re inserted. This could be confusing to users to see logs being shifted around, maybe too quickly to spot logs entries they are interested in.
Customisation
Logquacious used to have bespoke details on the intro/help text which have now been removed. It would be great to allow users to change it to the way they see fit.
Naively I thought you could get away with dynamically loading a Typescript tsx file that implements a certain interface, which did actually work in development mode. Unfortunately, TypeScript compiles down to JS, and we don’t really want a TypeScript compiler running in a browser, so that idea was scrapped.
The current plan is to allow users to use their own HTML, JS, CSS, etc files to be included dynamically. Possible options would be a HTML file to replace the text within the intro text, or to let the user change the theme completely. Even to rebrand if they feel the need to.
Miscellaneous
Ideally Logquacious should be backend agnostic. We will be looking at other backends to interface with. The code and configuration has already been set up so that adding new backends will not need (much) code refactoring.
Responsive design hasn’t been set up correctly yet. This definitely needs to be fixed for mobile/tablet users.
History and autocompletion would greatly increase productivity of users. Logquacious could fetch searchable fields and allow users to autocomplete fields too.
Final Notes
It has been a great journey so far working on this project, working with excellent people, and I hope to see more cool features in the future. If you’re keen on helping out, pick up an issue or just reach out on GitHub.