From 30 Minutes Down to 10: Taming our Monolith's CI Build Times
When Cash App was originally developed we had a single service powering all backend functionality, codenamed “Franklin”. Over time this approach didn’t scale with the size and structure of our engineering org and we’ve created many new microservices to serve our constantly growing set of Cash App features. We’ve been hard at work migrating code out of Franklin, but the size of the codebase has continued to increase. Many important bits of functionality still live in Franklin which means that developers often have to work in it. However, developing in Franklin is a frustrating experience due to code complexity, local development experience, and CI build times. Slow CI build times are particularly annoying as developers often have to push many changes (and thus incur many builds) before getting to a green build that is ready to merge.
When we started looking at improving build times toward the end of 2022 our p50 build time was 30 minutes and p99 was 45 minutes. After investing heavily in improving the state of our builds, we were able to reduce p50 build times to 10 minutes and p99 to 22 minutes, resulting in a huge quality-of-life improvement for engineers working in Franklin.
Why Is It So Slow Anyway?
Franklin has over a million lines of code and thousands of dependencies, so compilation takes a long time. We also have over 10,000 comprehensive integration tests that go through real-world scenarios such as creating two customers and testing sending payments between them, using an actual database. While these tests are great to validate that our code changes don’t break anything, they’re very slow to execute. To keep things somewhat manageable we shard tests across 200 workers, and ensure each test worker runs the same quantity of tests. However, since our tests take anywhere from one second to 30 seconds to complete, this meant that some workers finished much later than others, resulting in a slower build than we would expect.
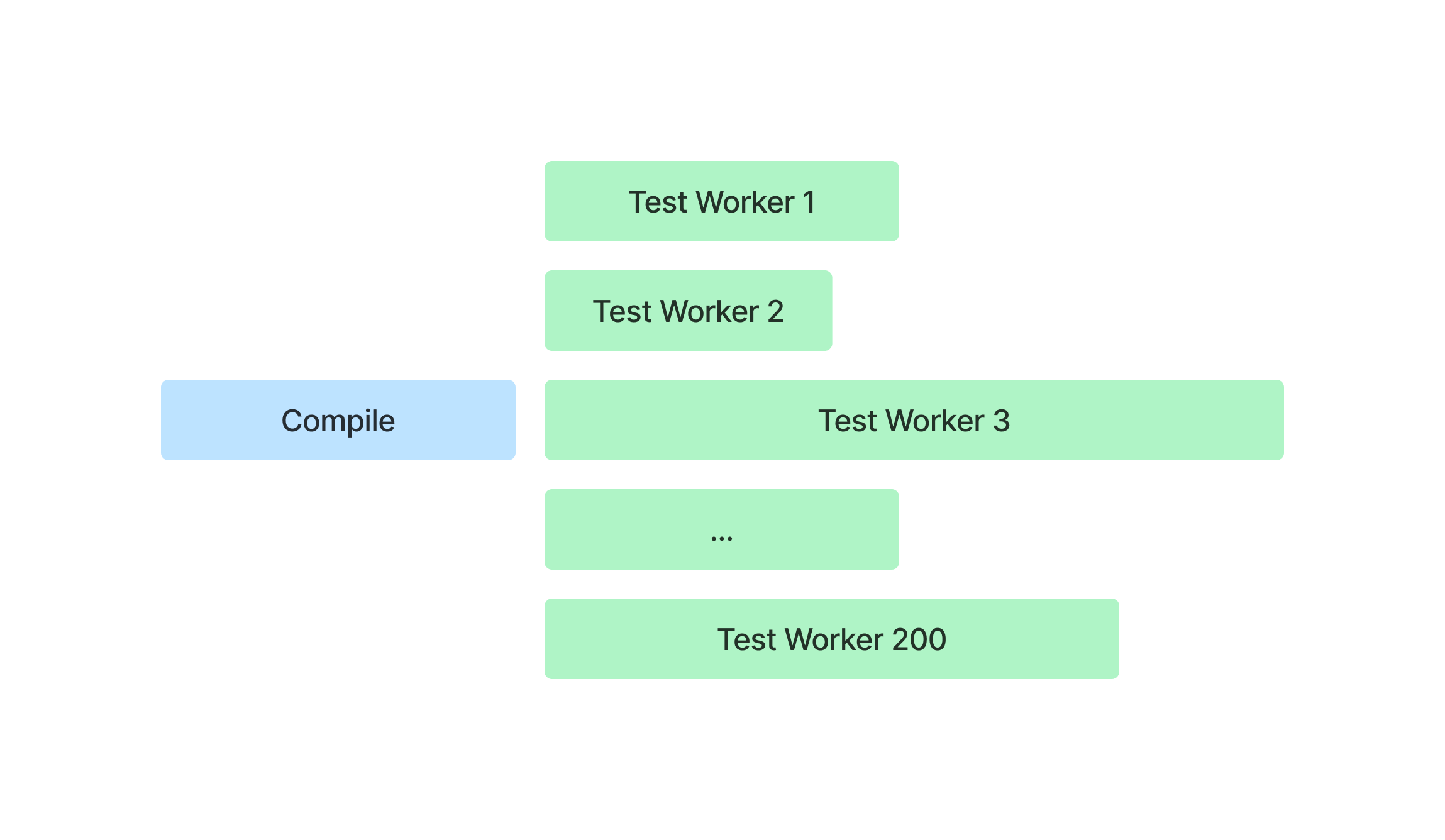
Our CI system used a shared pool of workers across many projects, and builds would occasionally encounter queuing delays waiting for a worker to become available. We also make use of spot instances, which are excess capacity that AWS provides at a much cheaper price point, with the caveat that they can be terminated at any time if AWS needs to reclaim them. While this reduces our CI cost, it slows down builds whenever we encounter a spot instance interruption.
Can We Throw Money at the Problem?
Could we speed up the build just by paying for more test workers? We quickly realized that this was extremely inefficient: each worker had to perform a lot of generic test setup before executing tests which meant a lot of money spent for not much value added. Furthermore, requesting more workers exacerbated our CI issues of queuing delays and spot instance interruptions, negating any speedup. Clearly, we were going to have to be a bit more clever.
Gradle Remote Build Cache
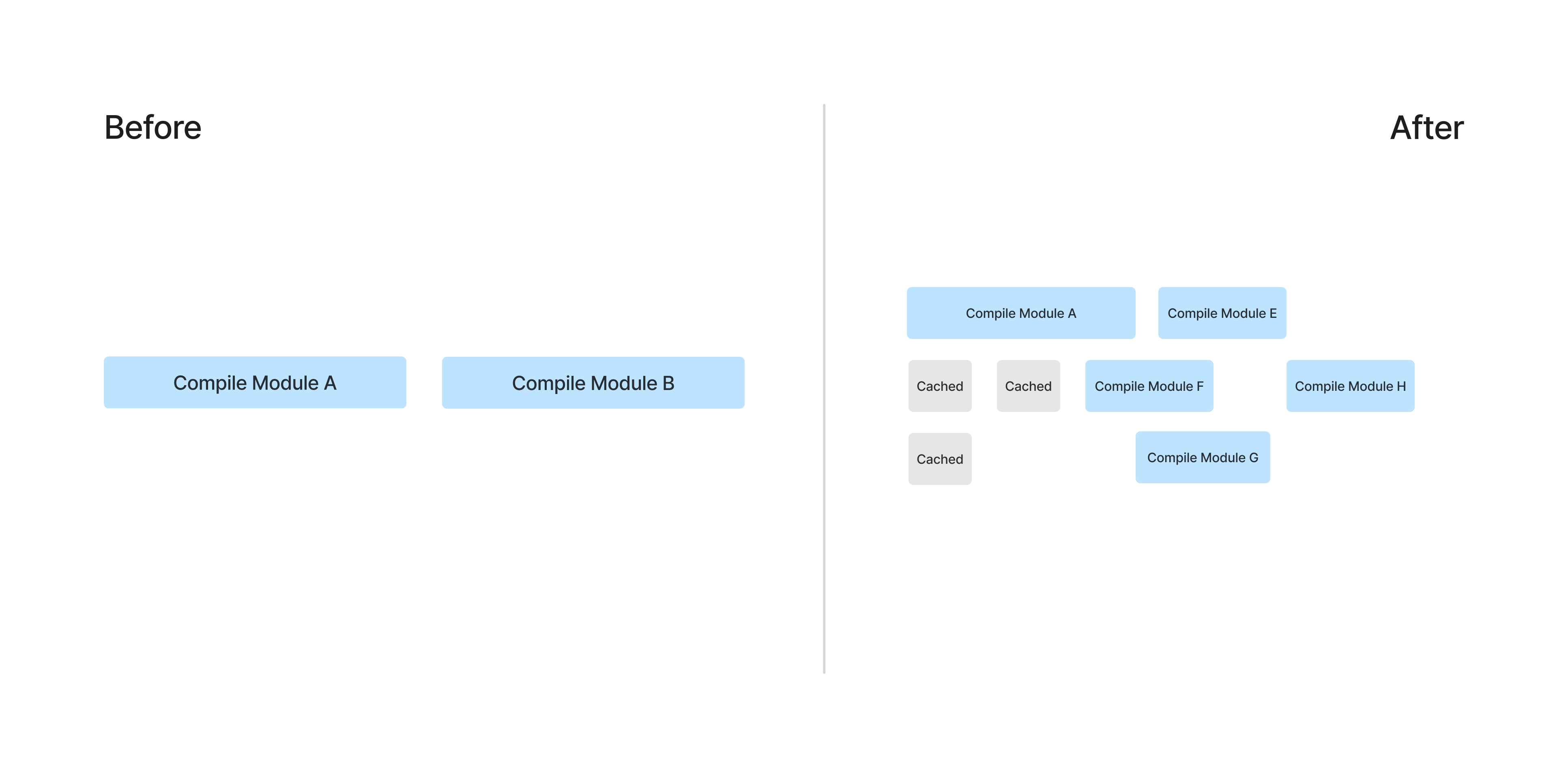
Gradle, our build tool, supports a remote build cache, to avoid rebuilding modules that haven’t changed from another build. While we had a rudimentary custom build cache previously, utilizing the remote build cache resulted in a much higher cache hit ratio. Now builds only have to recompile and run tests for modules that were changed in a specific PR, saving time that would have been wasted on rework.
Modularizing the Codebase
Though we had a few existing modules, the vast majority of the codebase existed in a single module. This is very bad for caching purposes, as any change to the module, no matter how insignificant, will cause the entire module to be rebuilt. We refactored and increased the modularization of the codebase, allowing us to benefit from a much higher cache hit ratio. Additionally, with more modules, more compilation was able to happen in parallel, reducing the total time of the compilation step.
Removing Dead Code
Franklin is our oldest codebase and had accumulated a lot of code that was no longer used. We spent some time identifying dead code and removing tens of thousands of lines of code and hundreds of tests.
Eager Test Worker Start
Originally we waited for the compilation step to complete before starting test workers for the test step. However, we realized there was a fair amount of setup the test workers could do while waiting for compilation, such as starting the database, applying migrations, and downloading dependencies. Starting test workers eagerly shaved several minutes off our builds.
Currently, we use a hardcoded delay before starting the test workers to strike a balance between build time and CI cost savings. However, this is rarely the exact optimal wait; sometimes we have the test workers waiting idle for many minutes before they can start executing the tests, and sometimes we don’t start the test workers early enough, resulting in a slower build than necessary. It would be more optimal to have a predictive delay based on the type of code change that would better reflect how long the compilation step is likely to take.
Build Step Optimization
We have various validation tasks that we perform as part of a build to ensure that our code meets security and quality standards. Previously, these were running in the critical path, slowing down builds. We moved these to a separate build step that runs in parallel with test execution, out of the critical path.
Better Test Distribution
Our simplistic approach of ensuring each test worker had the same amount of tests resulted in very lopsided test distribution; the fastest test worker would finish many minutes before the slowest. To mitigate this, we created a script to calculate the historical duration of each test and sharded tests based on these timings. This resulted in much more balanced build times across shards, and therefore faster overall builds.
This still isn’t an optimal approach due to random performance variation amongst the workers themselves, and in the future we would like to explore a queue based approach, where we don’t have to decide on the number of test workers in advance, and each test worker can pick tests off a queue until the queue is exhausted.
Test Customer Caching
Our integration tests require very expensive database setup to create test customers before we actually test the things that we care about. While the test customers are not identical across all tests, there are some configurations that are used by hundreds of tests. We created a way to cache these common test customers and re-use them on the next test run that required the same setup. We also integrated this caching into our test sharding logic so that tests with the same test customer requirements were distributed to the same test worker.
CI Build Platform Change
As part of a wider engineering change we migrated Franklin to a new CI system. The new CI system does not use spot instances and so doesn’t suffer from having to re-run test parts. Additionally, we have much better provisioning in the new worker pool, leading to low queue times. Finally, we use more powerful worker instances on the new system, speeding up compilation and test execution.
Putting It All Together
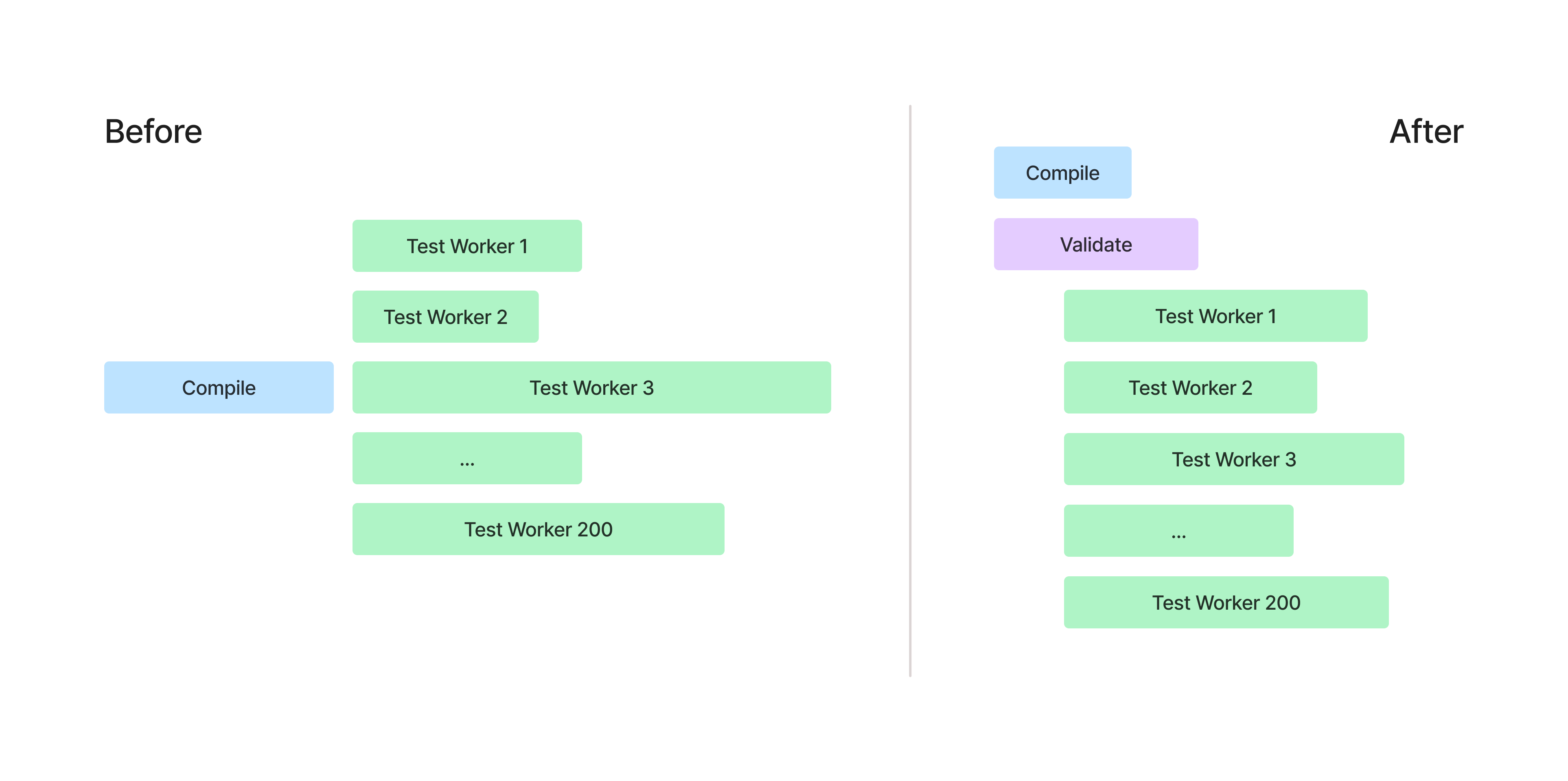
After applying the techniques described here we were able to reduce p50 build times from 30 minutes to 10 minutes and p99 build times from 45 minutes to 22 minutes, a drastic improvement over the previous build performance. We were also able to leverage our learnings from this project and apply some of these improvements to other services at Cash App, speeding up their builds as well.
With faster builds developers are able to spend more time working on the things that matter, making them more productive and happier.