Building a Data Science Platform in 10 days

Photo by Pietro Jeng on Unsplash
Context
At Afterpay, we are generating lots of data from customer transactions, website views and consumer referrals every day. Being able to derive insights from this data, and to use those insights to improve our consumer experience and provide value to our merchants and consumers, is a critical competitive differentiator for Afterpay.
Our growing data science and analytics team can easily query our data lake using SQL. The limitation of SQL is that it does not provide complex programmatic constructs and libraries that our data scientists need for advanced analytics and machine learning (ML). Thus, providing a cloud platform in which our data scientists can run R and Python code against our data, while maintaining the security and audit-ability of our data lake was an important problem to be tackled.
What did we set out to solve?
We worked closely with security and our data scientists to identify the following set of requirements:
1. Data security and privacy: This is the most important consideration for any data initiative at Afterpay. We want to ensure that our data does not leave our cloud environment. We also want to make sure any code run on our data is logged, and traceable to the individual to avoid inappropriate usage.
2. Smooth user experience: We wanted the system to use Okta (with the built-in MFA) for enabling users to use their corporate credentials (and not have yet another set of user and password to remember) and Cloudflare for network security to facilitate easy non-VPN access.
3. Scalability: The platform needs to be able to scale to a reasonable size, so that computationally heavy ML workloads can finish in reasonable time.
4. Optimize for self service: We want to minimize operational dependency on the platform team. Data scientists should be able to self-serve most of their daily work needs, including installing libraries and scheduling regular jobs.
5. User friendly learning curve: We prefer languages such as Python and SQL our users are already familiar with, so that they can focus on delivering business value, rather than forcing them to learn more engineering-focused technologies like Apache Spark, needed to get most out of certain commercial platforms .
6. Timely: We wanted to deliver a solution that helped with an urgent business opportunity. Some vendor solutions looked promising. However, the time it required to evaluate and implement necessitated a need for a quick parallel solution to be put in place.
How did we overcome them?
JupyterHub emerged as one of the early candidates for proof of concept, because our data scientists were already using Jupyter notebooks on their laptops. It features multi-user support and a rich set of integrations to single-user Jupyter notebook servers. We especially like its modular architecture, as portrayed below:
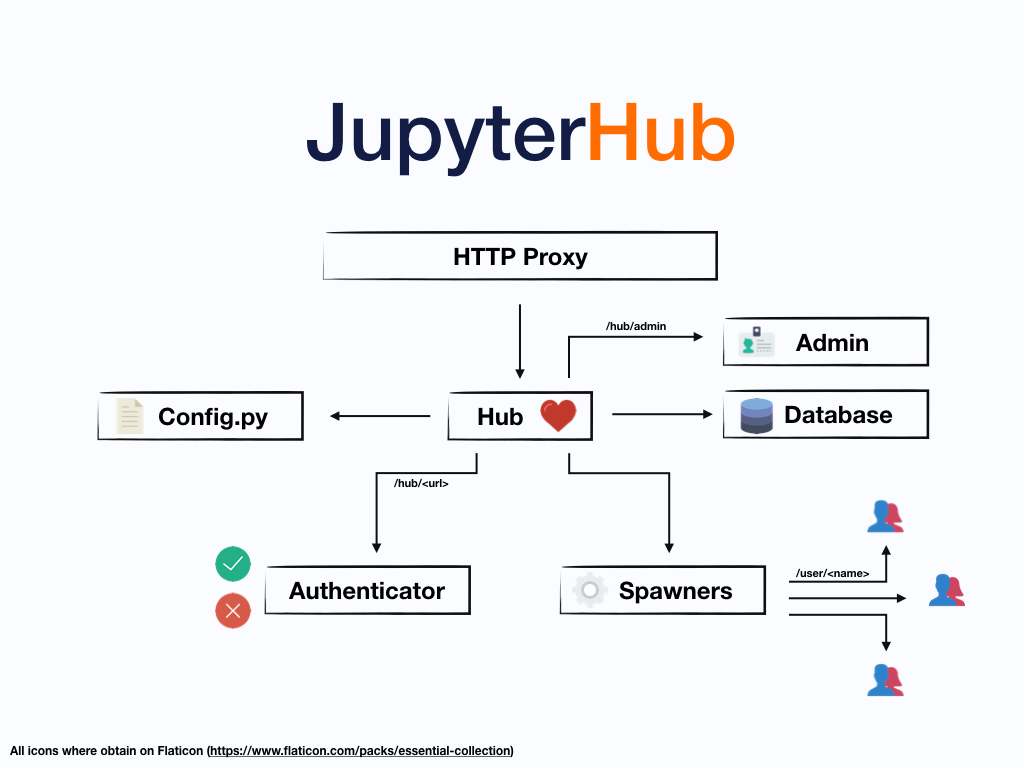
(Image Courtesy: JupyterHub Documentation)
Being open source and with a large community of contributors made it possible for us to make use of ready-to-use custom modules, as needed.
Multiple deployment options is available for JupyterHub:
- The Littlest JupyterHub (TLJH): This is a single machine deployment option developed for small scale use, aimed at sub 50 user use cases.
- Zero to JupyterHub: This is a Kubernetes deployment option, developed and used for large scale operations. Most notably, it is used at the UC Berkeley DataHub program.
After comparing the two, we decided to go with TLJH. K8s seemed like a lot of complexity for an MVP. In addition, Afterpay had only 2 data scientists and ~ 20 analysts at the time, and the 50 user limit of TLJH was well within our allowance.
During our exploration of TLJH, we followed Kent Beck’s timeless advice
“Make it work, Make it right, Make it fast”.
- We started with a trial deployment in our development AWS environment. It was as simple as ssh-ing into an EC2 box and running an install script. After that, we immediately opened the platform for our data scientists to try. We also took one of their existing scripts, and made sure that it could run on the platform. This process took only a single day.
- After getting the initial feedback, we decided that we got enough positive signal to proceed to production. We used our infrastructure best practices: creating AMIs using Packer and Ansible and using Buildkite to manage the CI/CD; using Terraform to manage the AWS infrastructure; Kitchen to run tests against the infrastructure. This was a time consuming process and took us a week to get right, but doing so enabled us to confidently make future changes and enhancement to the platform.
- After our first production deployment, we started rolling out custom integrations for Okta and Cloudflare. Without going into too much detail, we forked the jwt authenticator, made some changes to it and integrated with cloudflare argo. The result is that as long as the user is logged into Okta, and are allocated to an authorized group, they can navigate to JupyterHub and they are automatically logged in as their Okta user. This also removed the dependency on VPN / SSH jumping, even if the server is hosted in a private subnet.
- Finally, to ensure that our users have easy access to our cloud data warehouse, we wrote a small library to leverage AWS IAM services to give our users temporary access, that is attached to their Okta identity. The complexity is abstracted away from the user, and they can get a Pandas data frame as simple as the code below:

Thanks to this focus on essentials, we were able to provide a fully operational solution in under ten days!
We opened access to all data science and analytics users soon afterwards. We continued to take feature requests, such as S3 integration, notebook scheduling, better monitoring, self-annealing, and implemented them as enhancements. Six months later, we had around 25 weekly active users, and more than 10 machine learning models developed and shipped to production using the platform.
What did we learn?
- The biggest learning for us was the power of solving business problems quickly, without worrying about creating the perfect solution . If you are reading closely, we actually failed to meet requirement 3. Being hosted on a single VM makes it simple, but it does not meet the definition of scalability (having a very big EC2 server does not count). The server sometimes crashes due to memory issues (we spent another 4 hours on it and set up a simple automated rebooting process which took care of most of the pain). However, it solved multiple critical business problems and accelerated machine learning model development at Afterpay, with significantly improved data security.
- User requirements are better understood through actual usage and iteration, and it is very hard to predict what they will be in advance. Some of the most popular features and requests for the platform were the ability to schedule notebooks and share results with others. We had thought Spark integration and TensorFlow would have been high on the list, but in the end nobody asked. Therefore, we should aim for putting real workload and users onto our product as early as possible, as opposed to building advanced features that users may not need.
- Ship fast, but don’t compromise on security and deployment best practices. As urgent as the request was, we did not ship the platform with access to any production data until we got identity / network security right, had security review done, and set up properly using Infrastructure As Code best practices. This ensured that we could confidently and swiftly deliver features to the platform, while opening up to an increasing number of users
What next?
There are, of course, things we have not been able to solve with this platform:
- Scalability and resilience: A single EC2 server is neither scalable nor resilient. If it goes down, with it any running notebook.
- Gap between experimentation and productionization: JupyterHub is currently an interactive experimentation form. After you get a ML model to train in a notebook, there is still a lot of work to be done before the model can be productionised
- Scheduling jobs lacks monitoring/notification/retry: If you schedule a notebook on the server, you do not get those features that Apache Airflow provides out of the box.
The best outcome of this quickly launched platform was that now we have a better understanding of user needs which can help us with conducting effective vendor exploration. To solve some of the problems, we are looking at the K8s deployment options for JupyterHub mentioned before. We also would not exclude completely tearing the platform down in favour of a vendor product or another self hosted solution, if it is significantly better at meeting the now well understood requirements. At Afterpay, we are always encouraged to not be limited by what already exists. When we started this project a mere 9 months ago, we had 2 data scientists as our target users. Now we have more than 10 times that in 4 continents. The business grows and changes at light-speed, and so should we.
Sounds Interesting?
Interested in joining us in a Data Engineering role and help us improve lives for millions of consumers around the world, every day? Consider joining our team